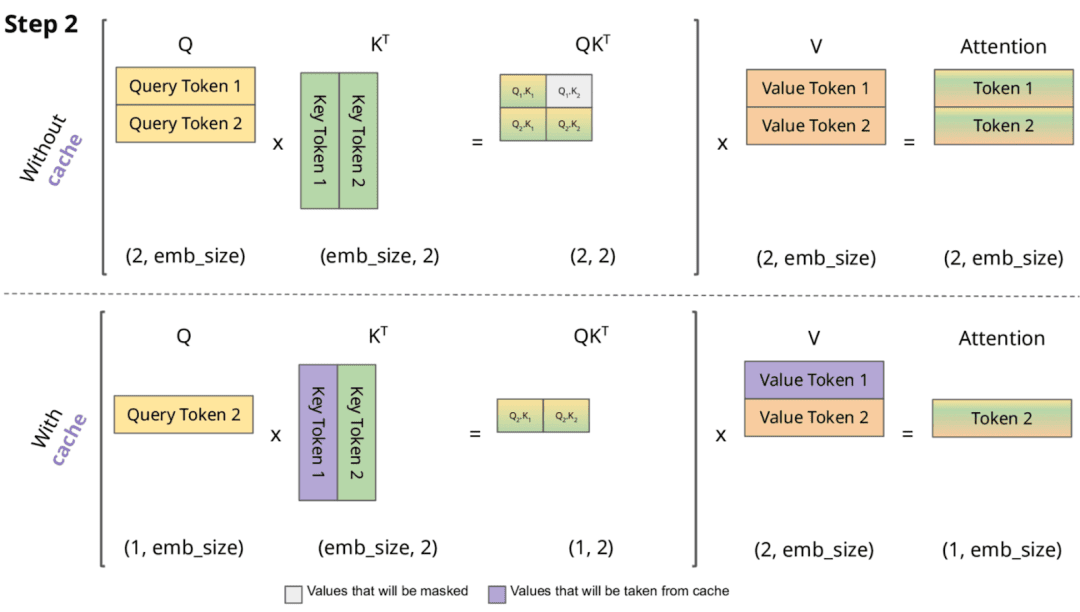
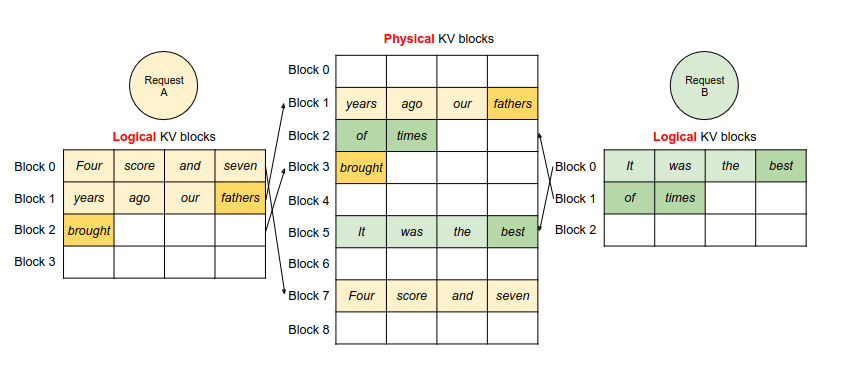
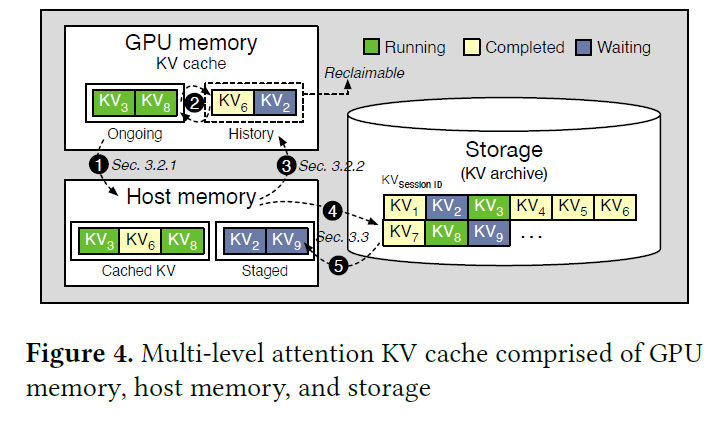
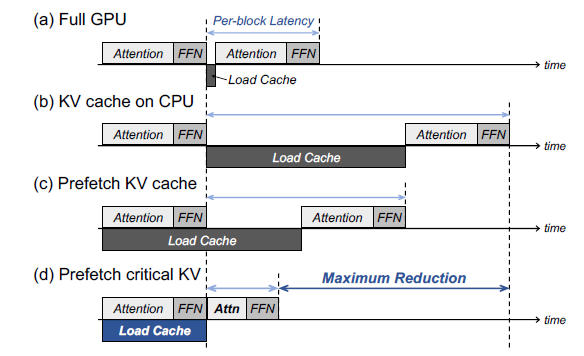
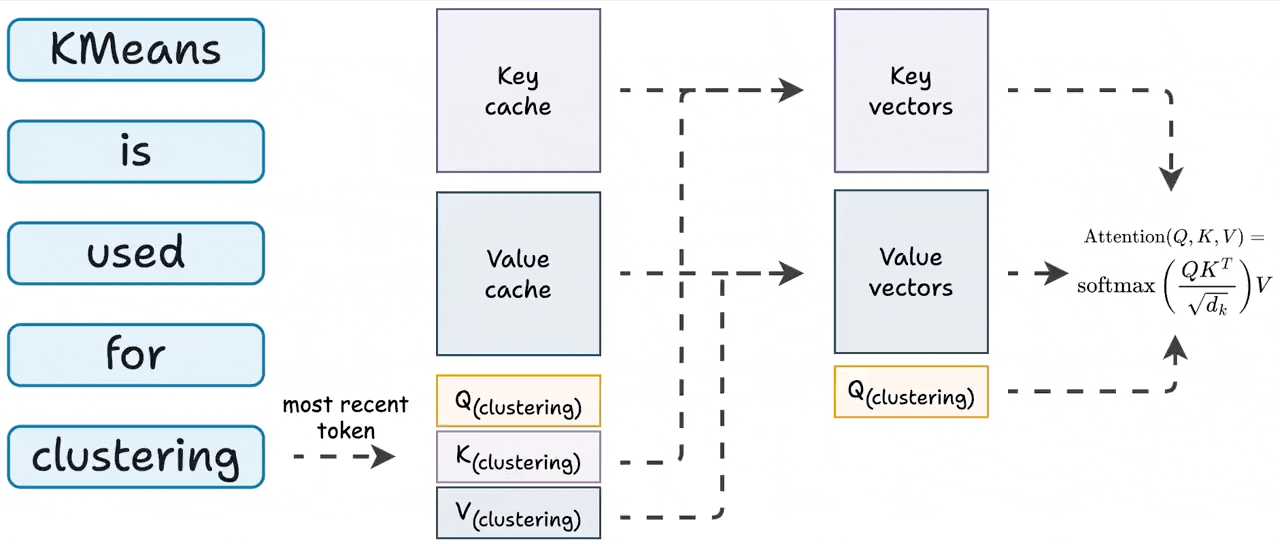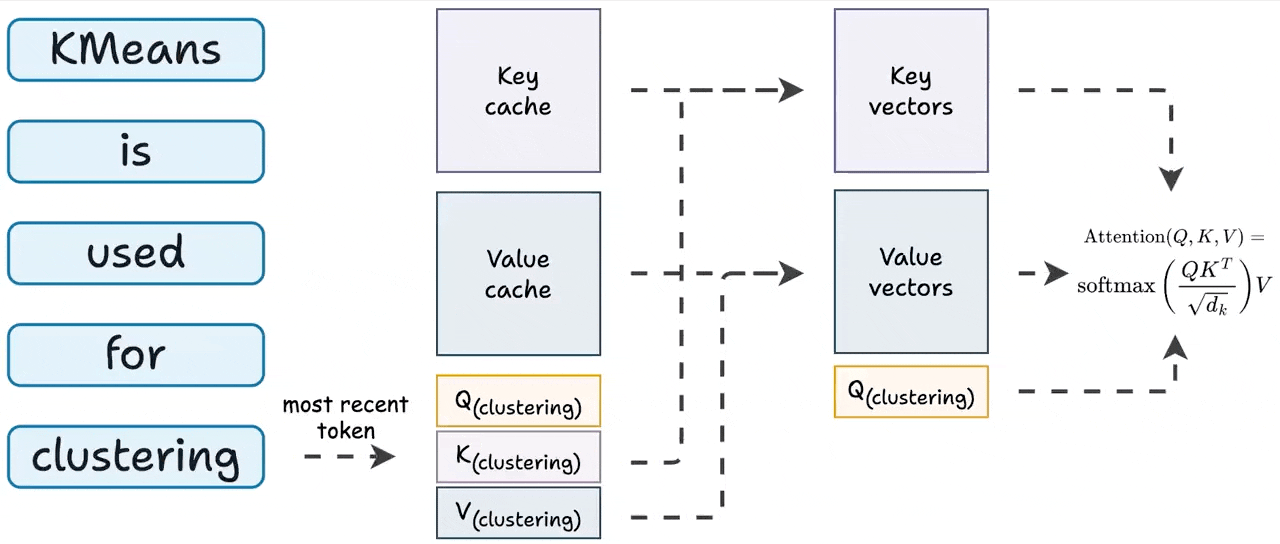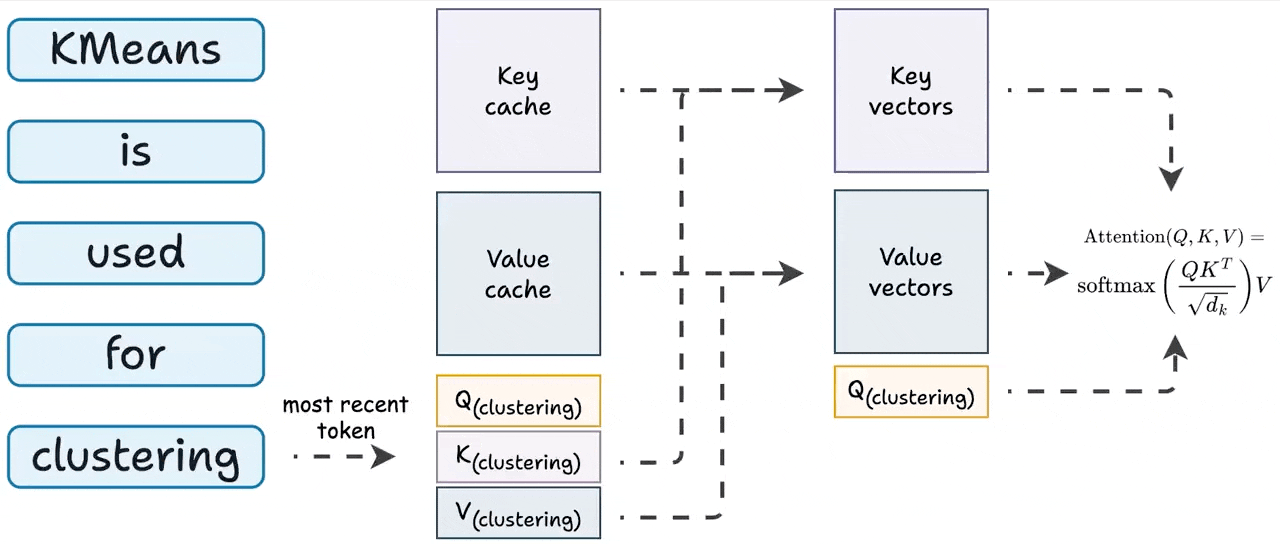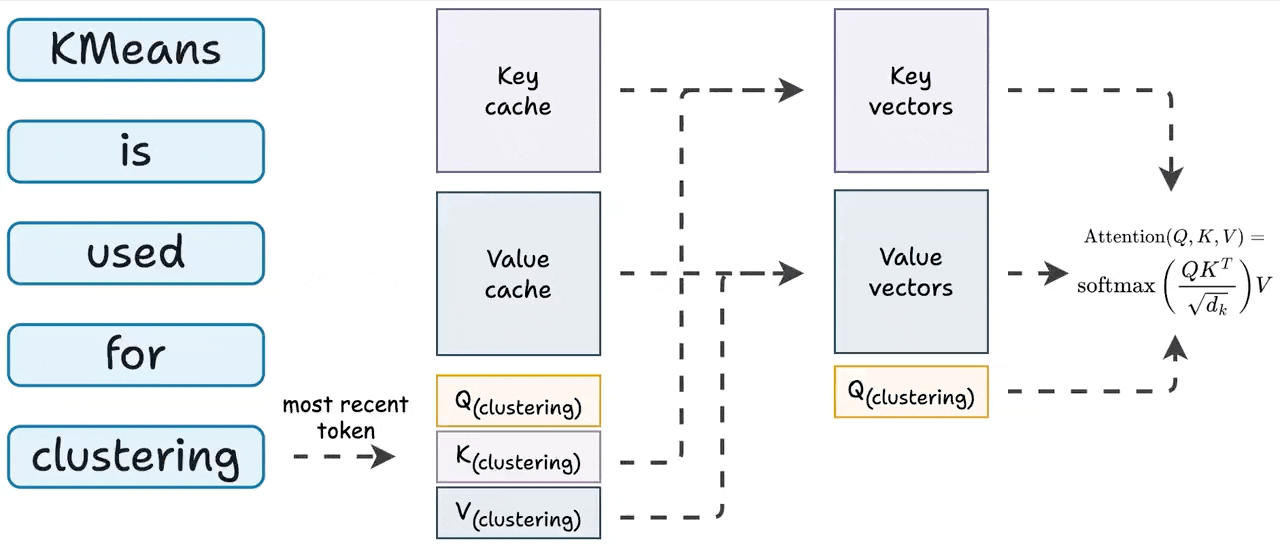
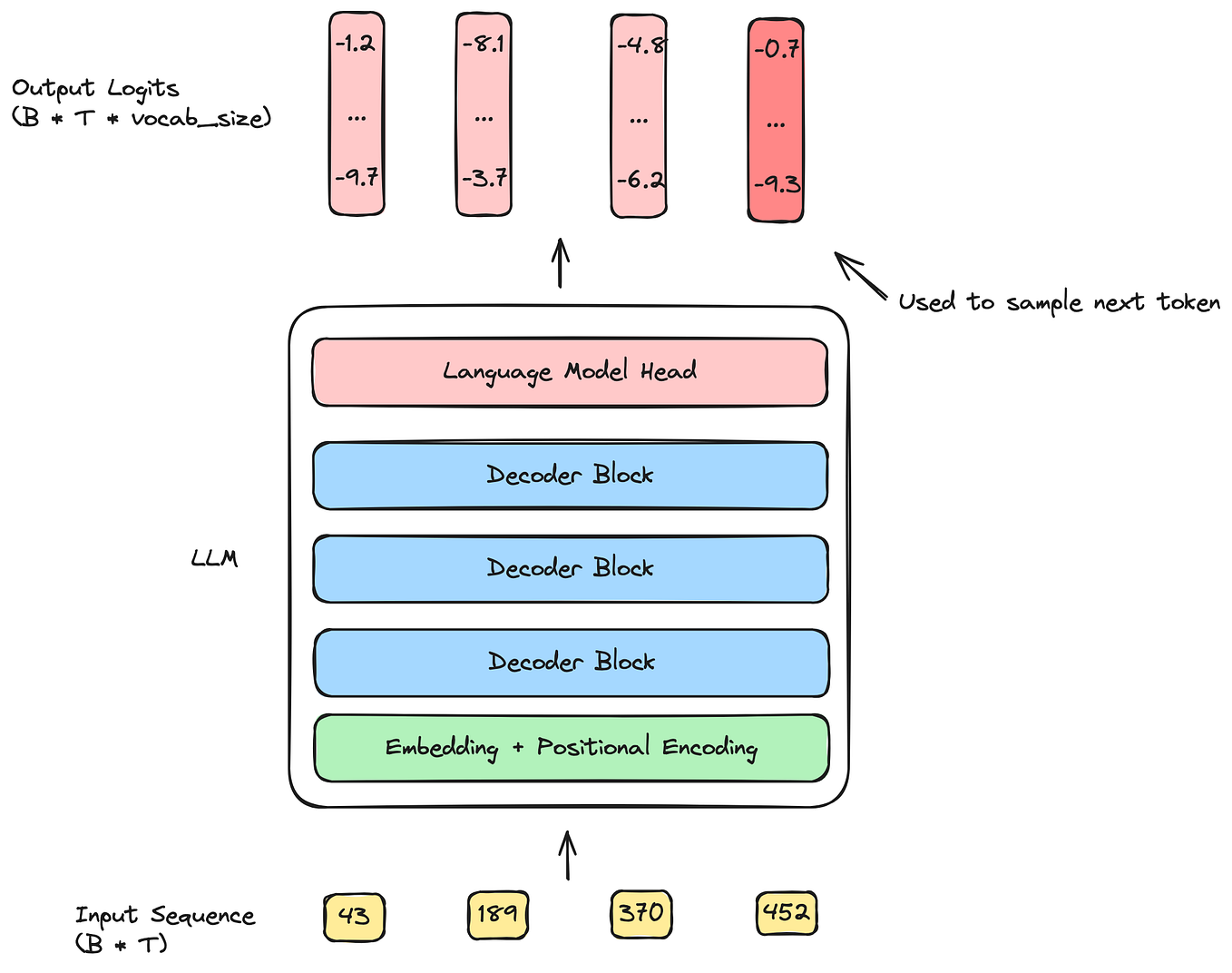
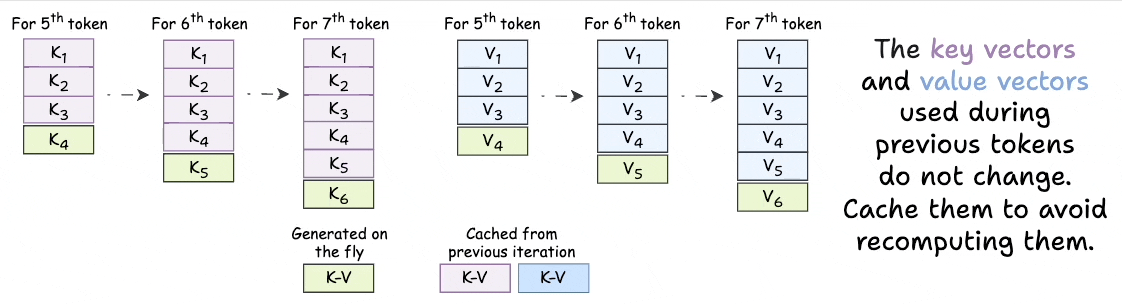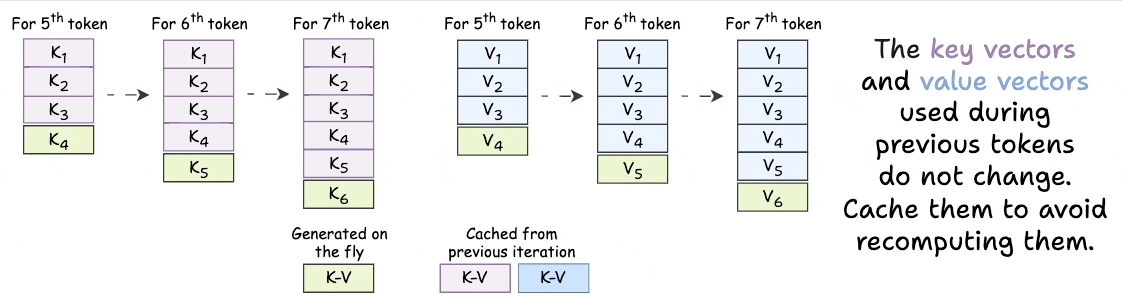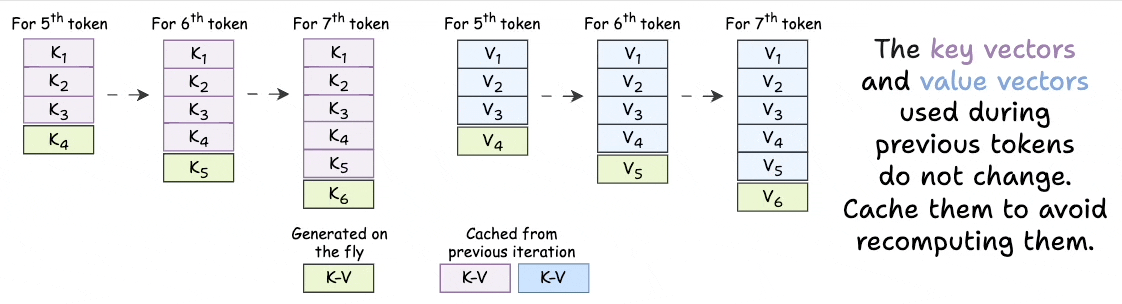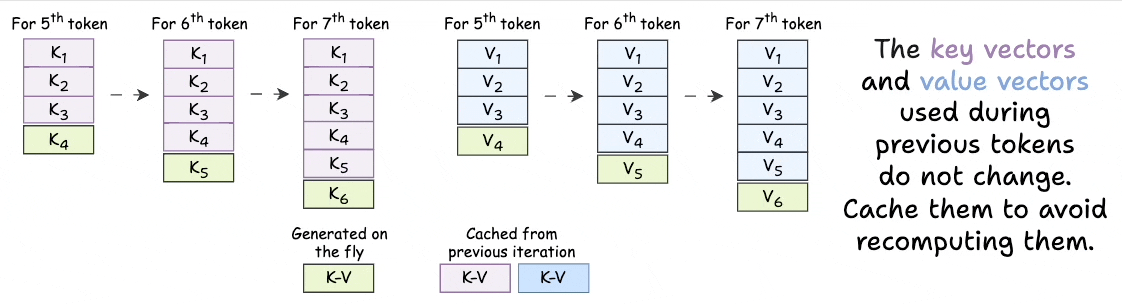
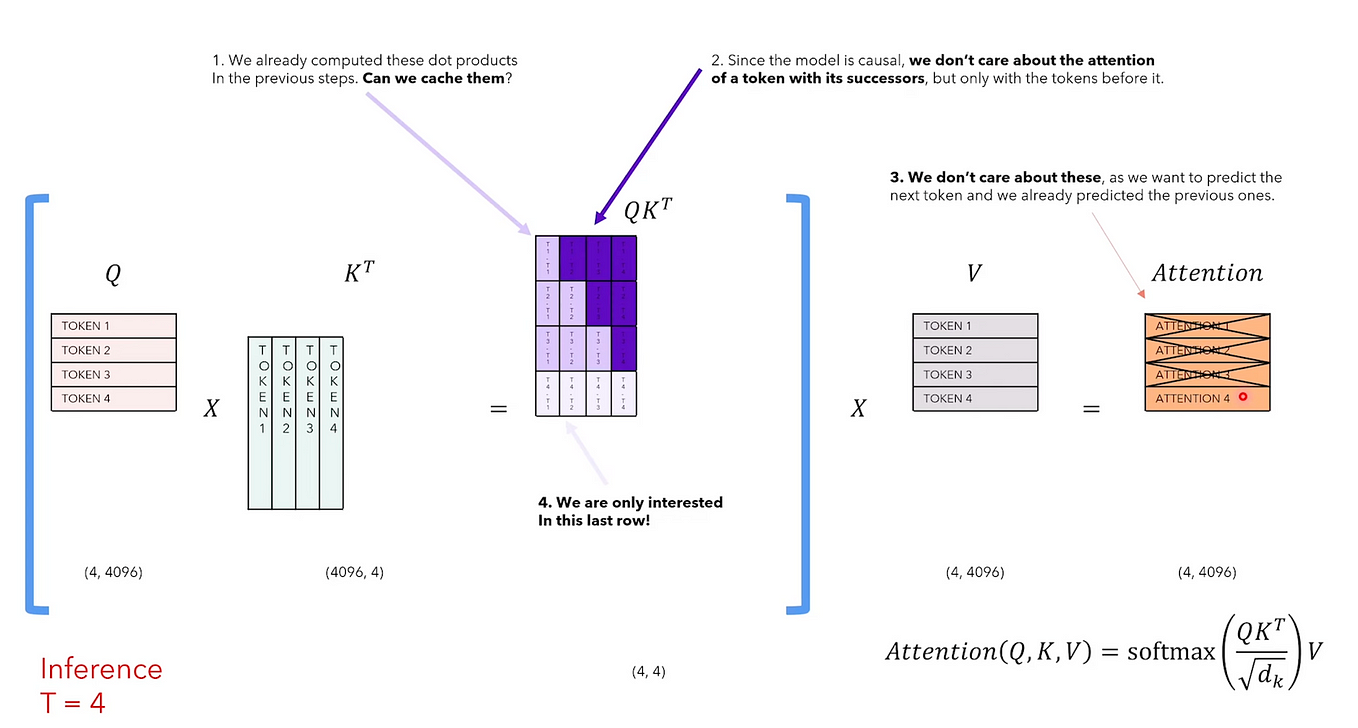
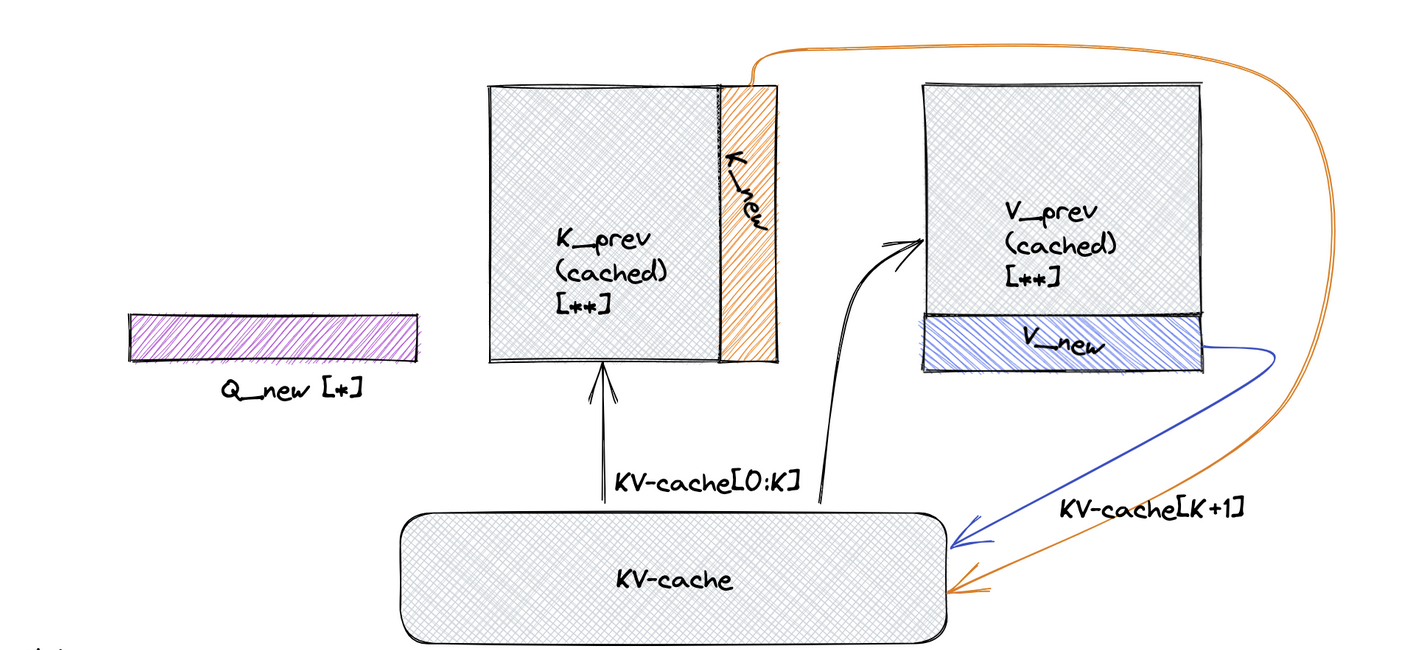
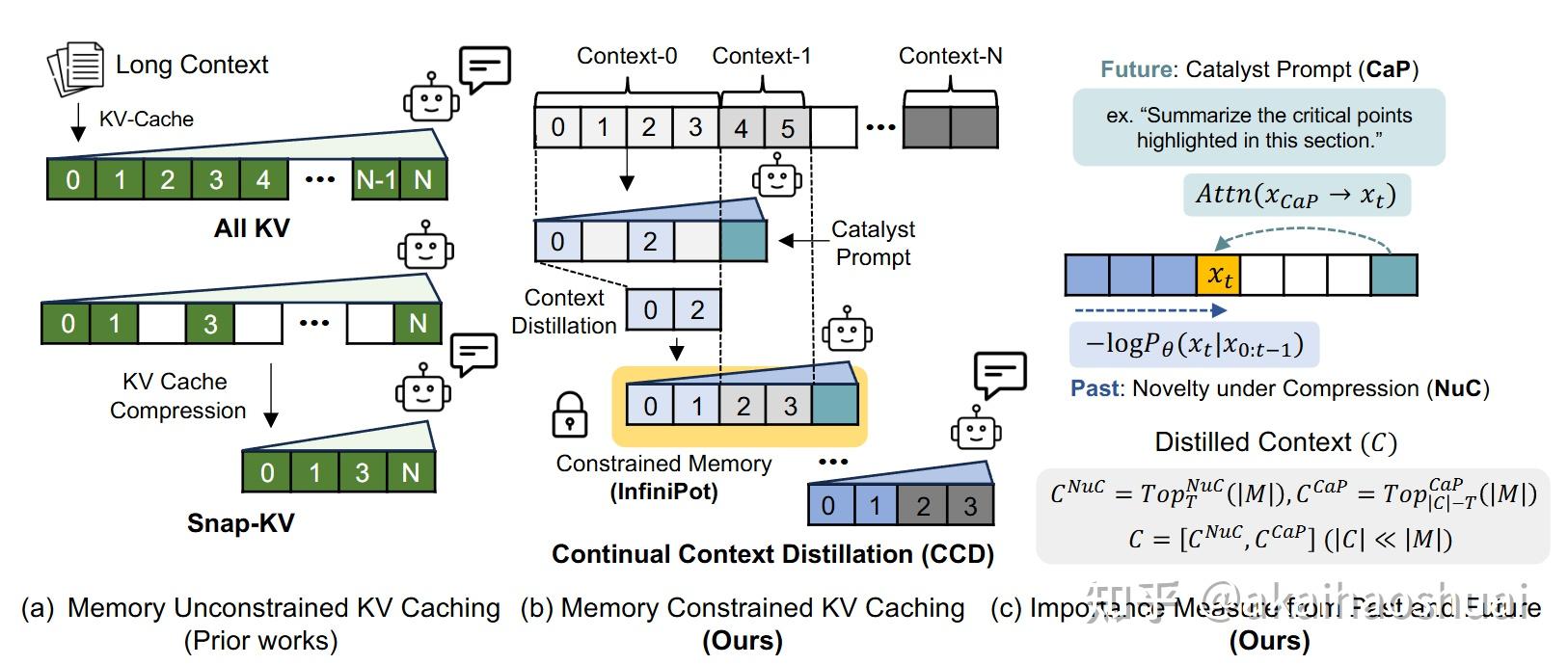
Showing 119 of 119on this page. Filters & sort apply to loaded results; URL updates for sharing.119 of 119 on this page
Memory Optimization in LLMs: Leveraging KV Cache Quantization for ...
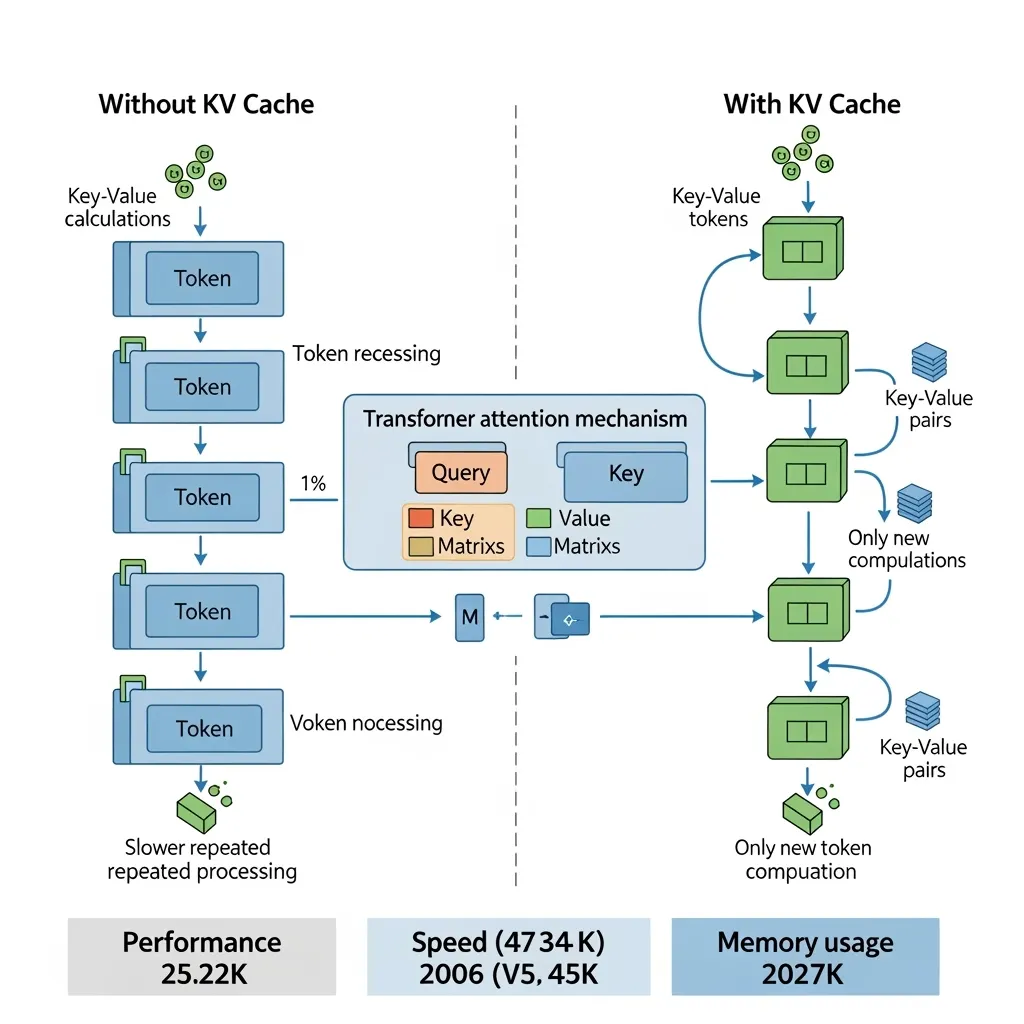
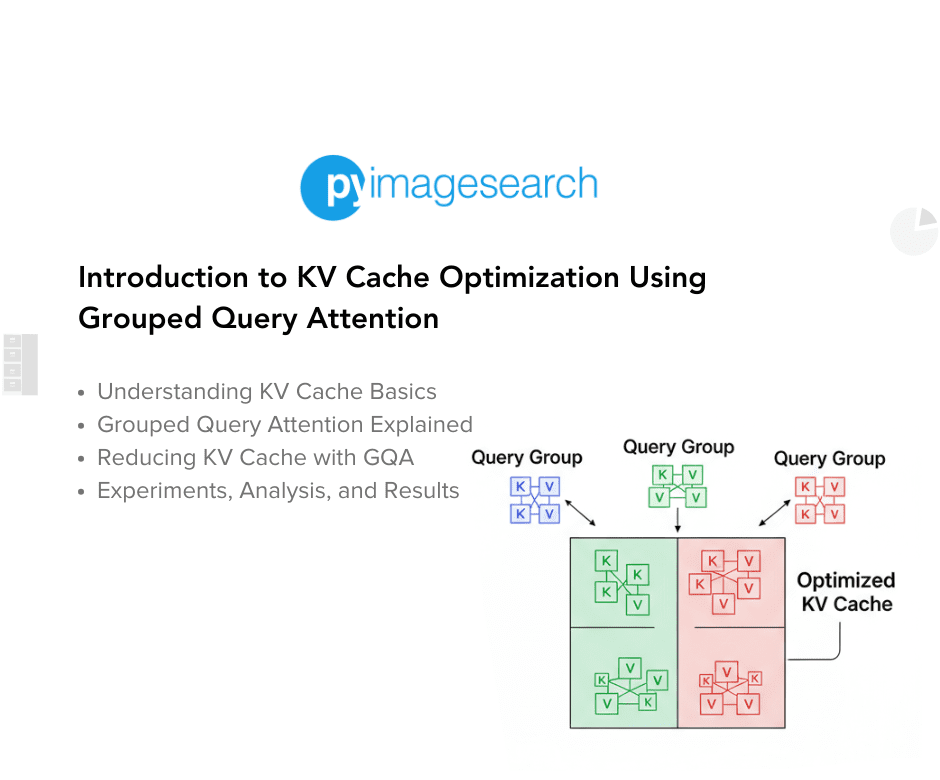
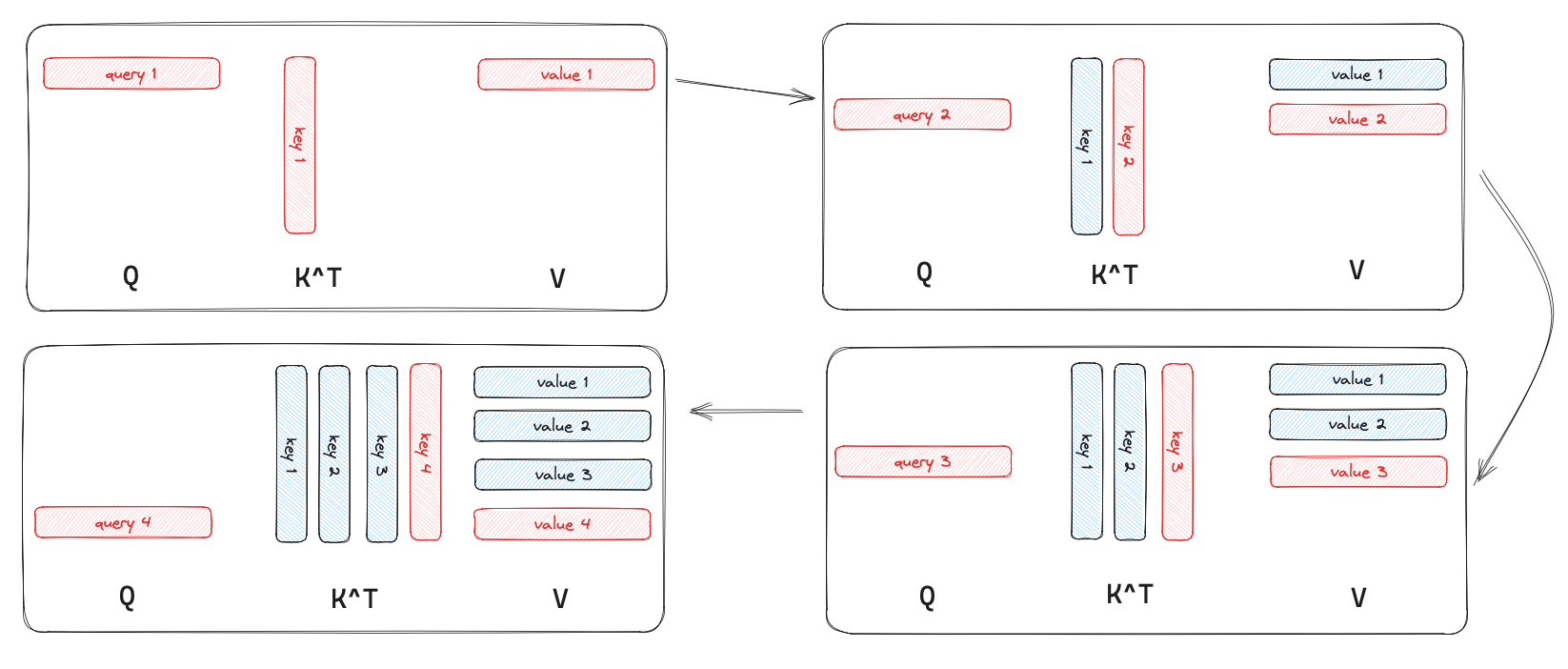
Introduction to KV Cache Optimization Using Grouped Query Attention ...
KV Cache Optimization via Tensor Product Attention - PyImageSearch
LLM inference optimization - KV Cache - MartinLwx's Blog
Techniques for KV Cache Optimization in Large Language Models
LLM profiling guides KV cache optimization - Microsoft Research
KV Cache Optimization — Why Inference Memory Explodes and How to Fix It ...
Everything about Model Inference -2. KV Cache Optimization | by ScitiX ...
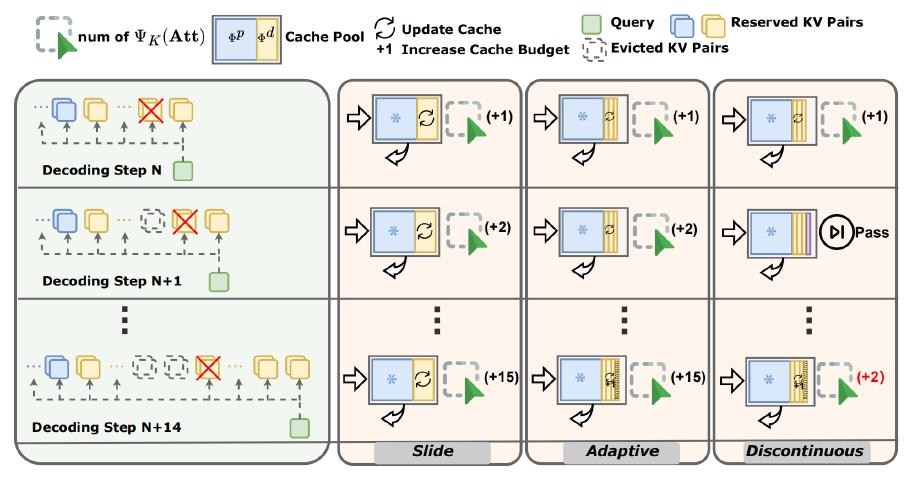
SCOPE: KV Cache optimization framework for long-context generation in ...
KV Cache and Memory Optimization | david6666666/vllm-omni | DeepWiki
PureKV: Plug-and-Play KV Cache Optimization with Spatial-Temporal ...
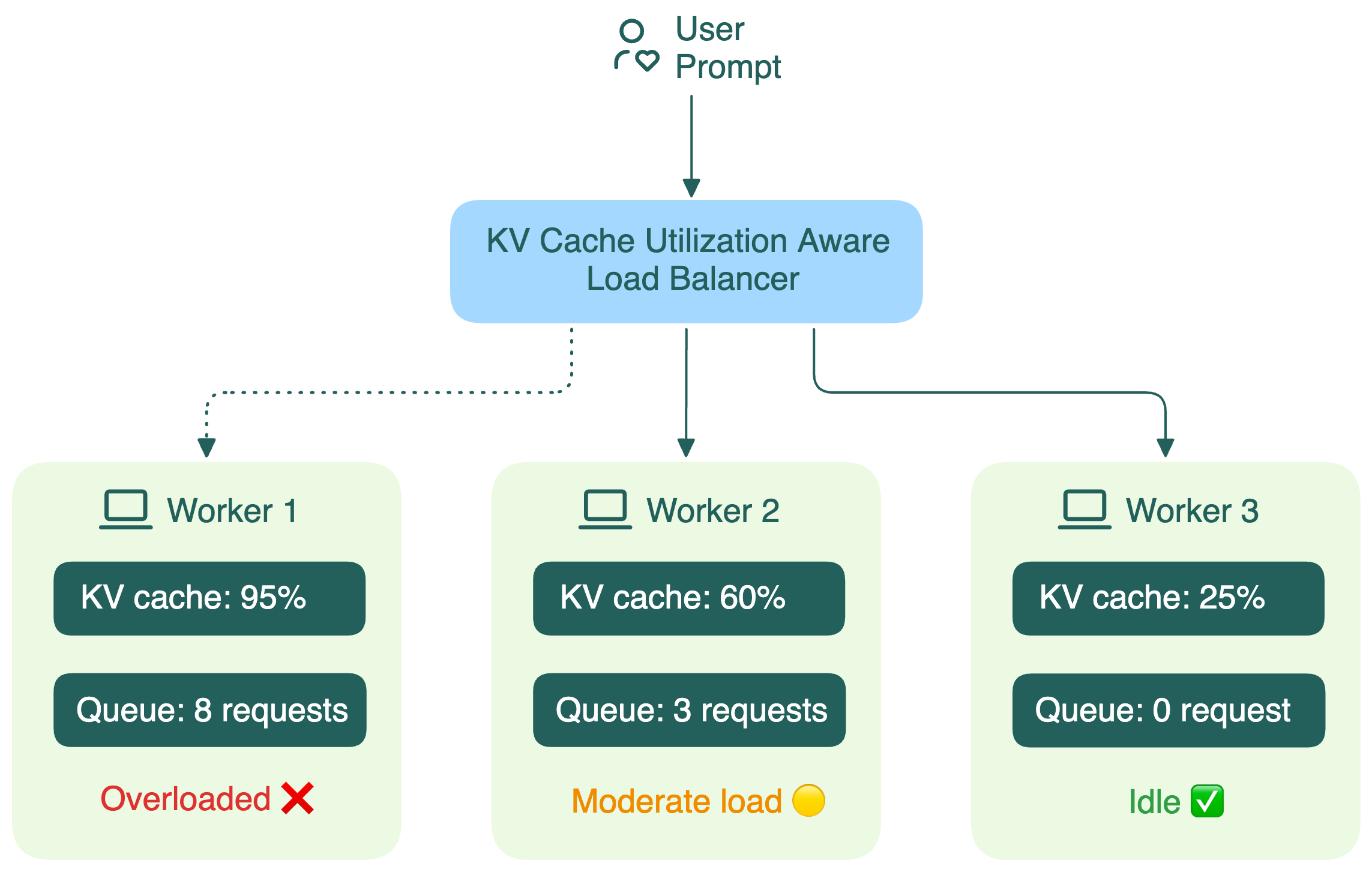
KV cache utilization-aware load balancing | LLM Inference Handbook
LLM Inference — Optimizing the KV Cache for High-Throughput, Long ...
Optimizing LLM Inference: Managing the KV Cache | by Aalok Patwa | Medium
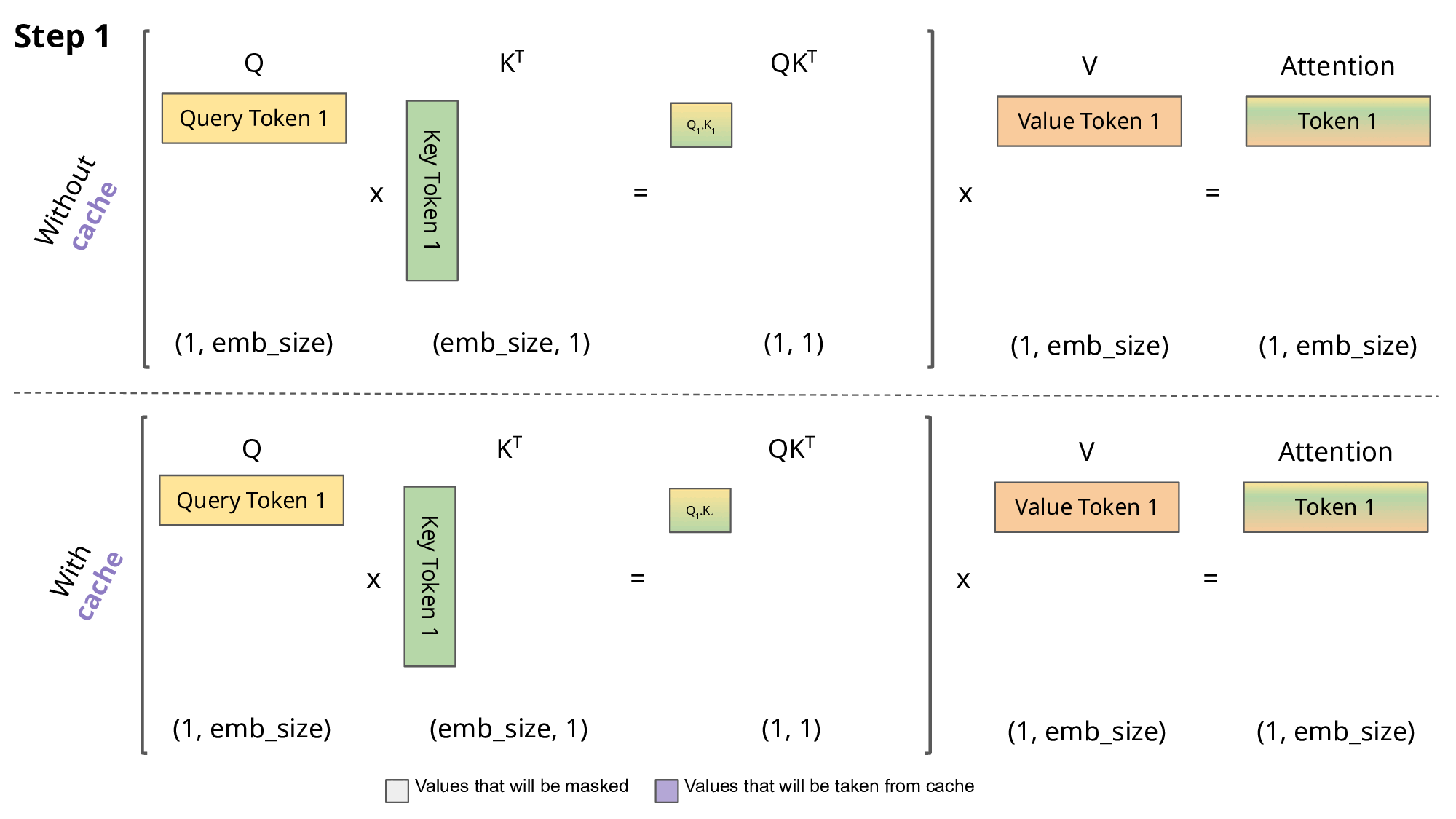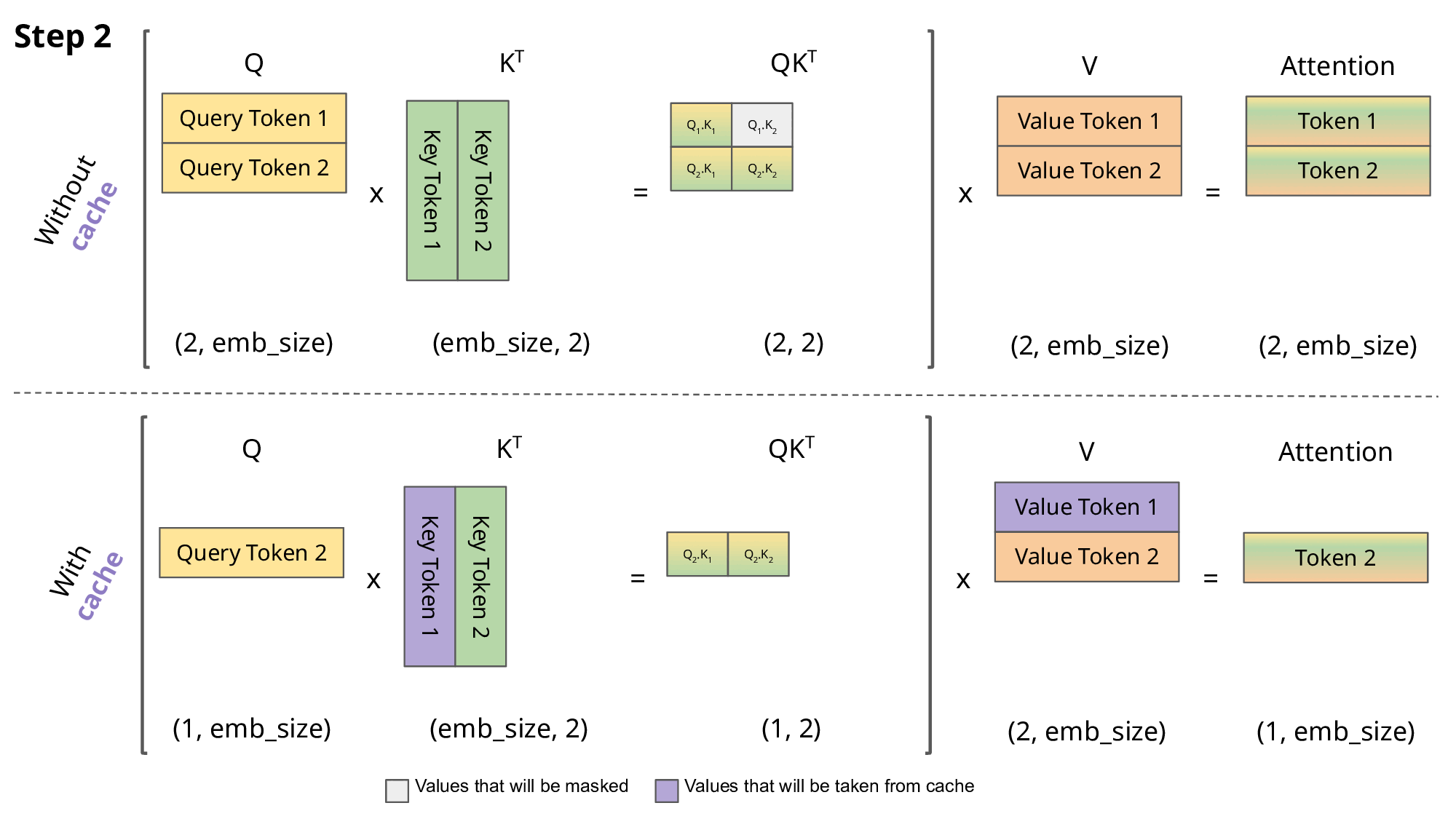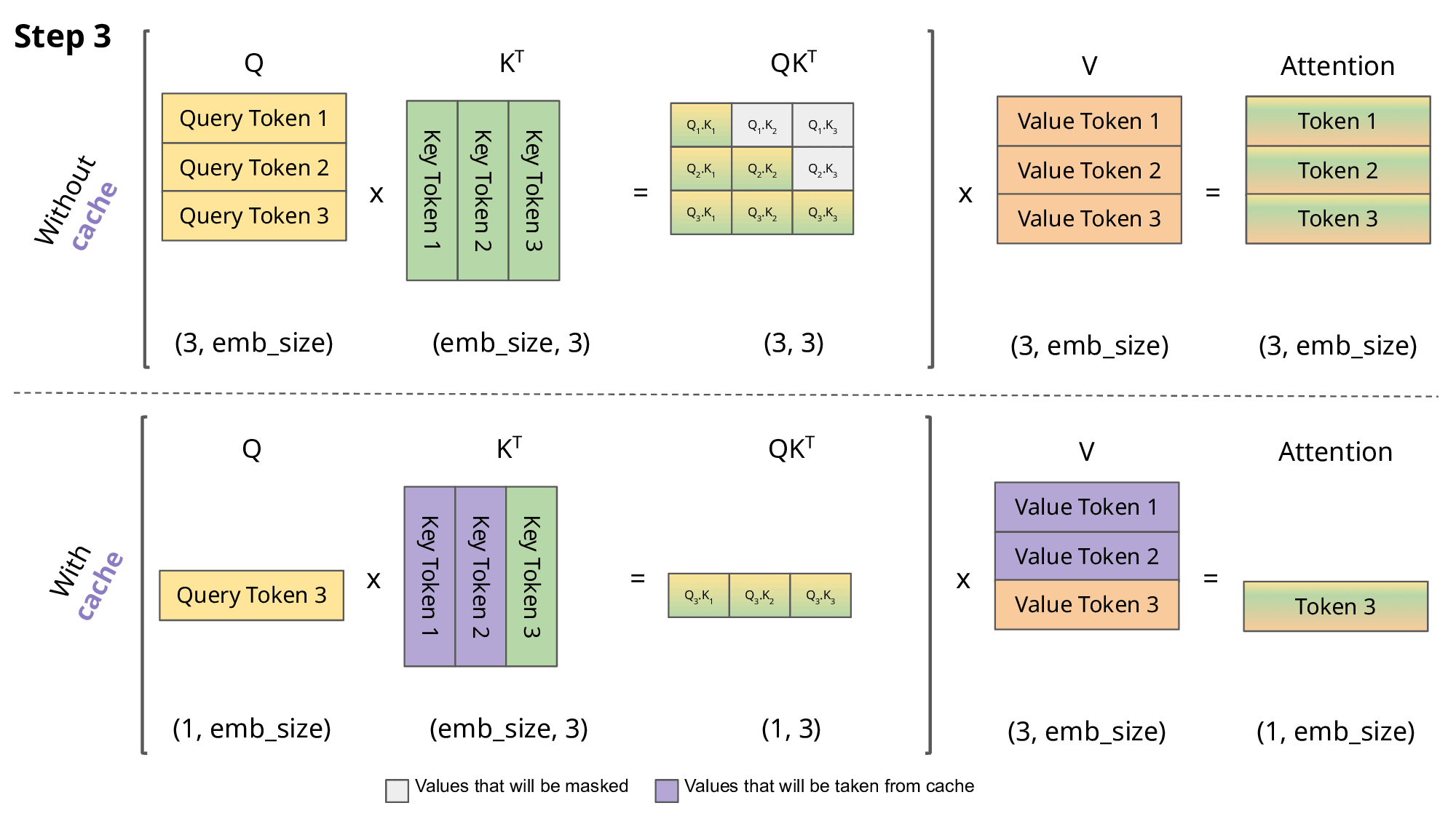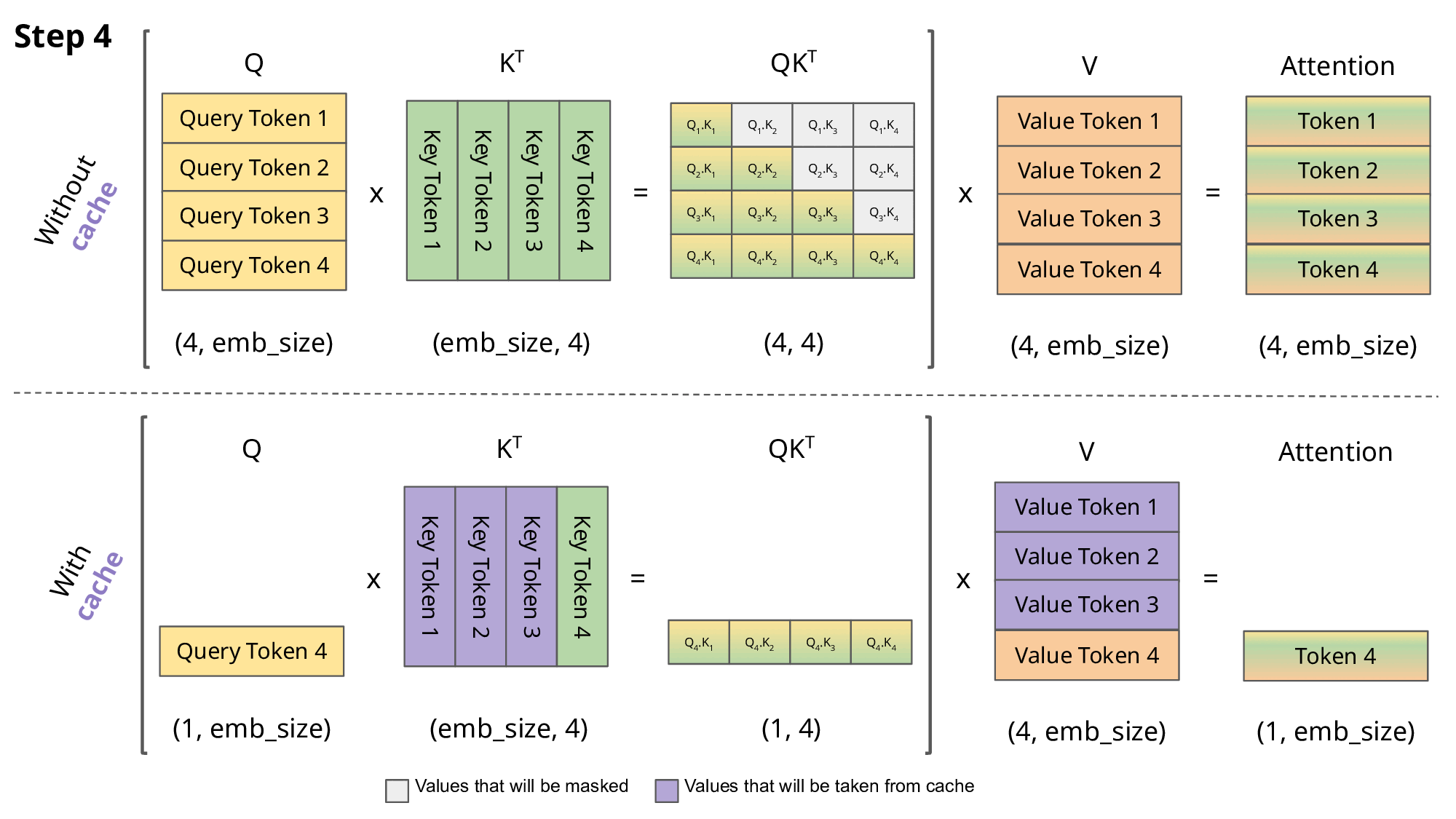
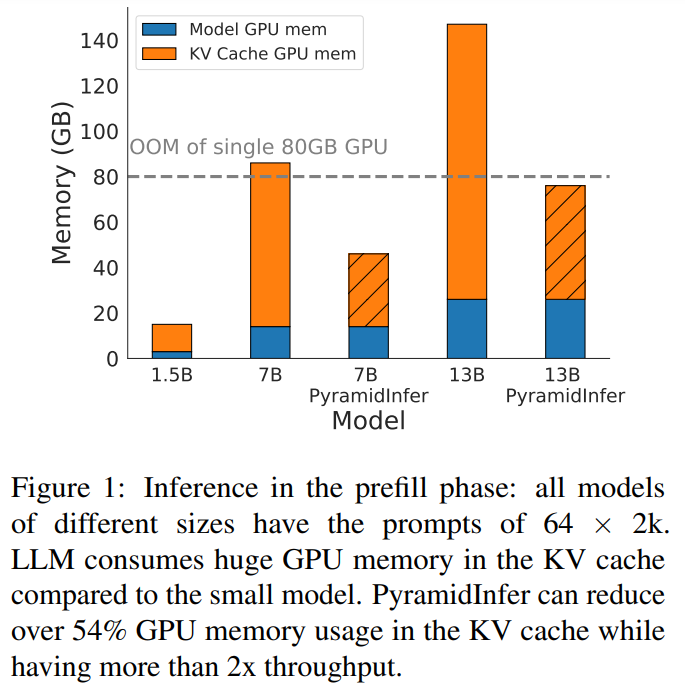
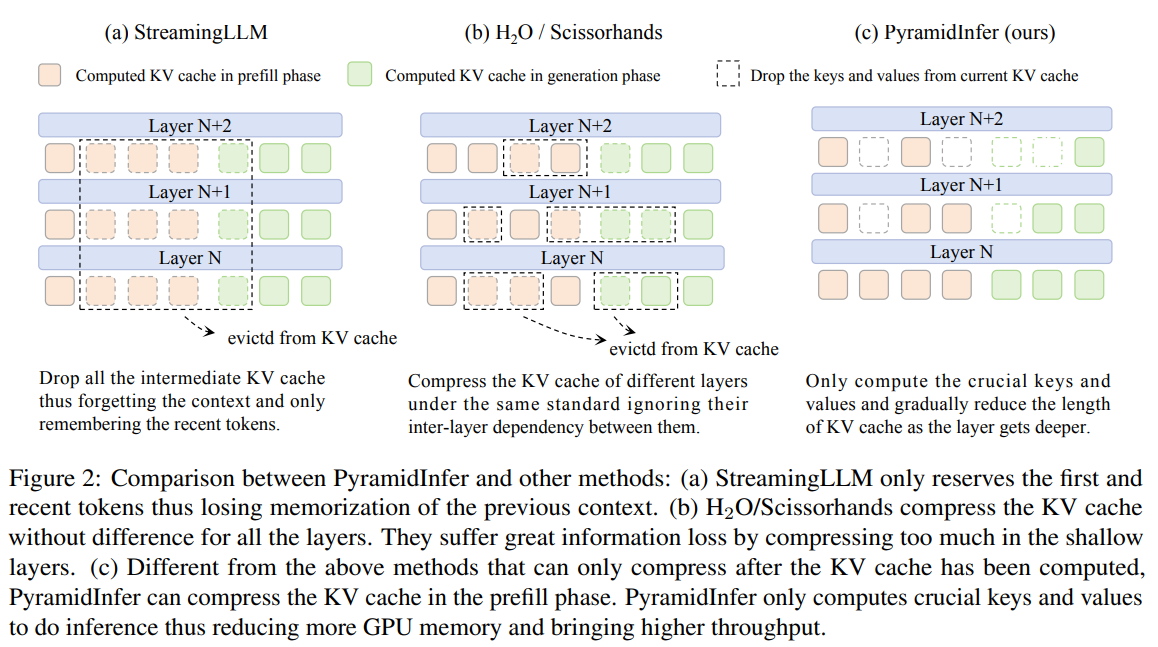
PyramidInfer: Allowing Efficient KV Cache Compression for Scalable LLM ...
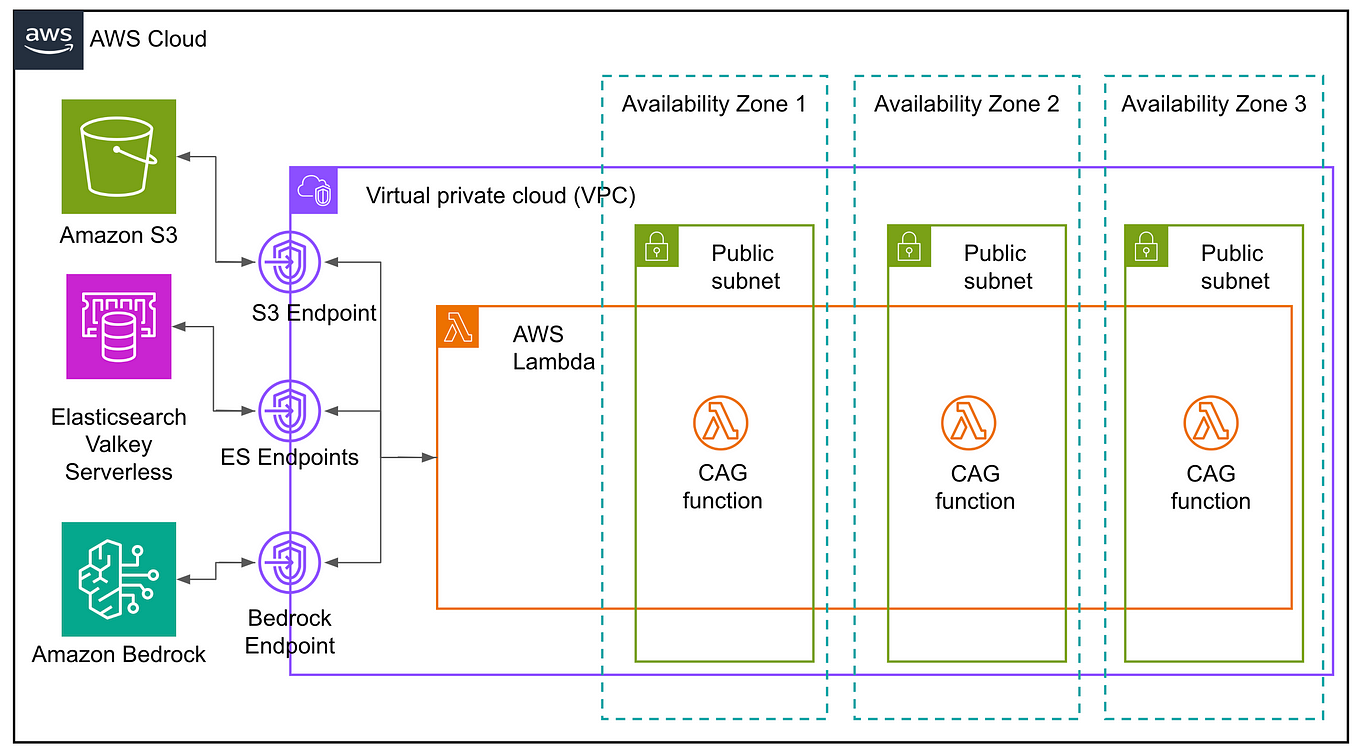
Scaling Multi-Turn LLM Inference with KV Cache Storage Offload and Dell ...
Understanding KV Cache and Paged Attention in LLMs: A Deep Dive into ...
How KV Cache Works & Why It Eats Memory | by M | Foundation Models Deep ...
KV Cache 详解:新手也能理解的 LLM 推理加速技巧-CSDN博客
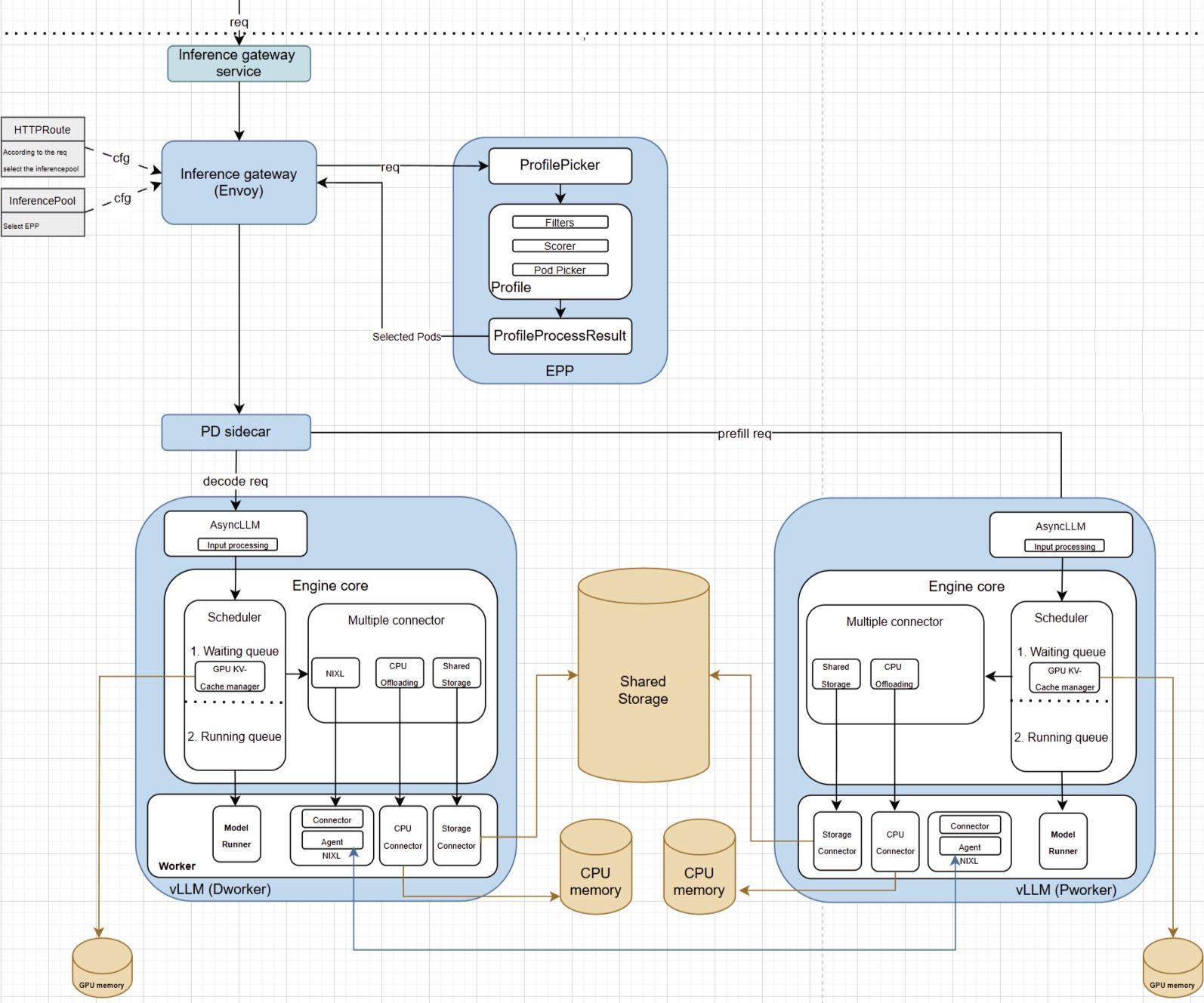
Master KV cache aware routing with llm-d for efficient AI inference ...
LLM 推理的 Attention 计算和 KV Cache 优化:PagedAttention、vAttention 等_paged ...
KV cache 缓存与量化:加速大型语言模型推理的关键技术 - 知乎
KV Cache is a very important technique to improve LLM inference latency ...
Introducing New KV Cache Reuse Optimizations in NVIDIA TensorRT-LLM ...
KV Cache in Large Language Models: Design, Optimization, and Inference ...
Welcome to my blog! - Understanding KV Cache
5x Faster Time to First Token with NVIDIA TensorRT-LLM KV Cache Early ...
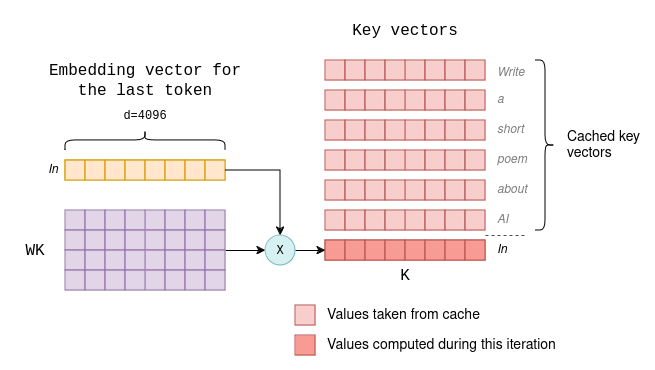
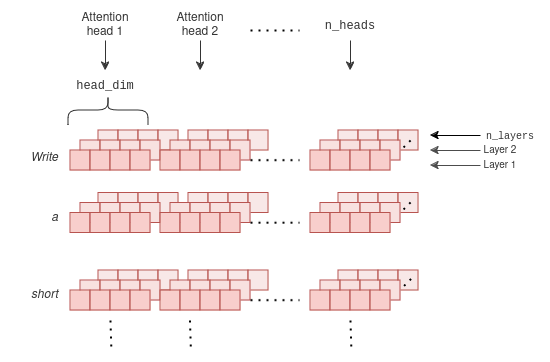
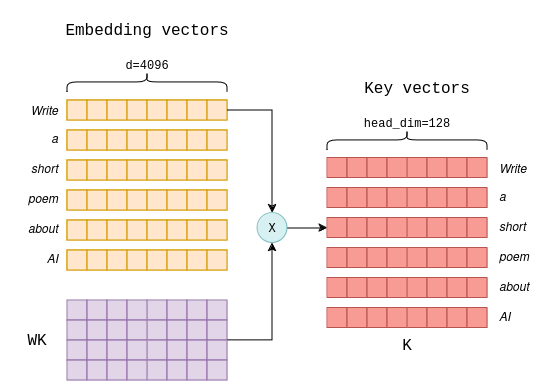
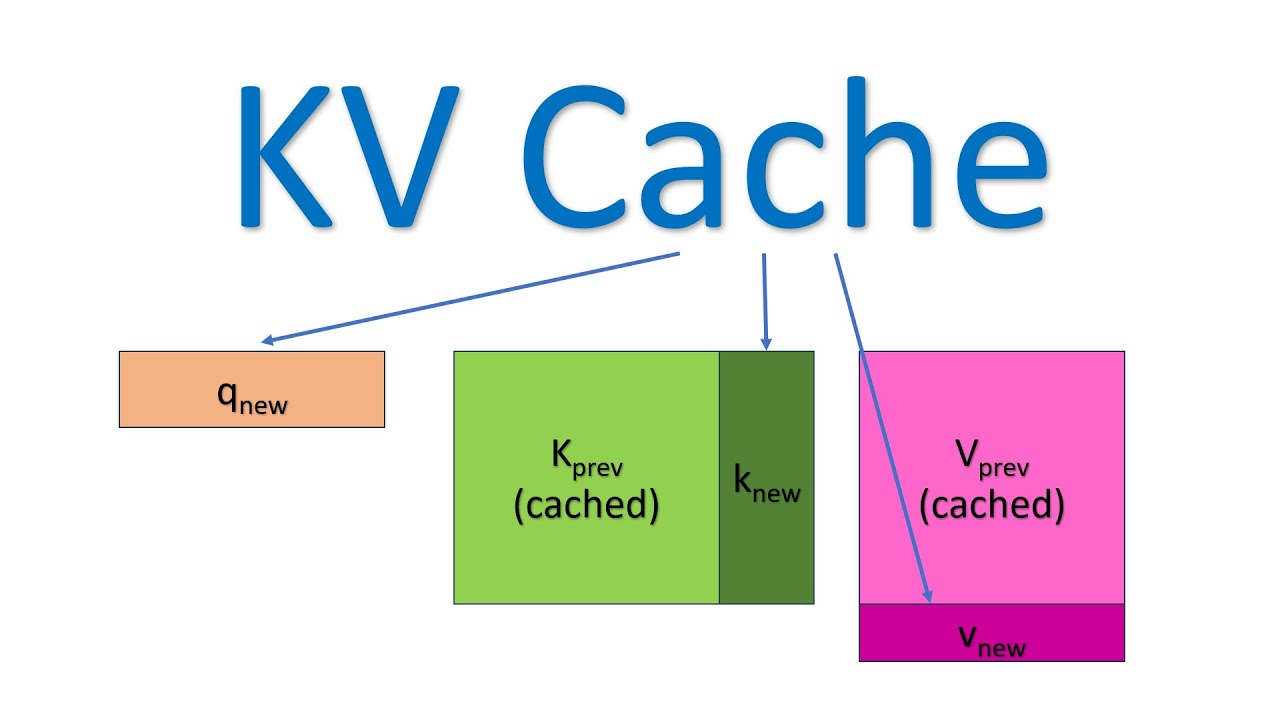
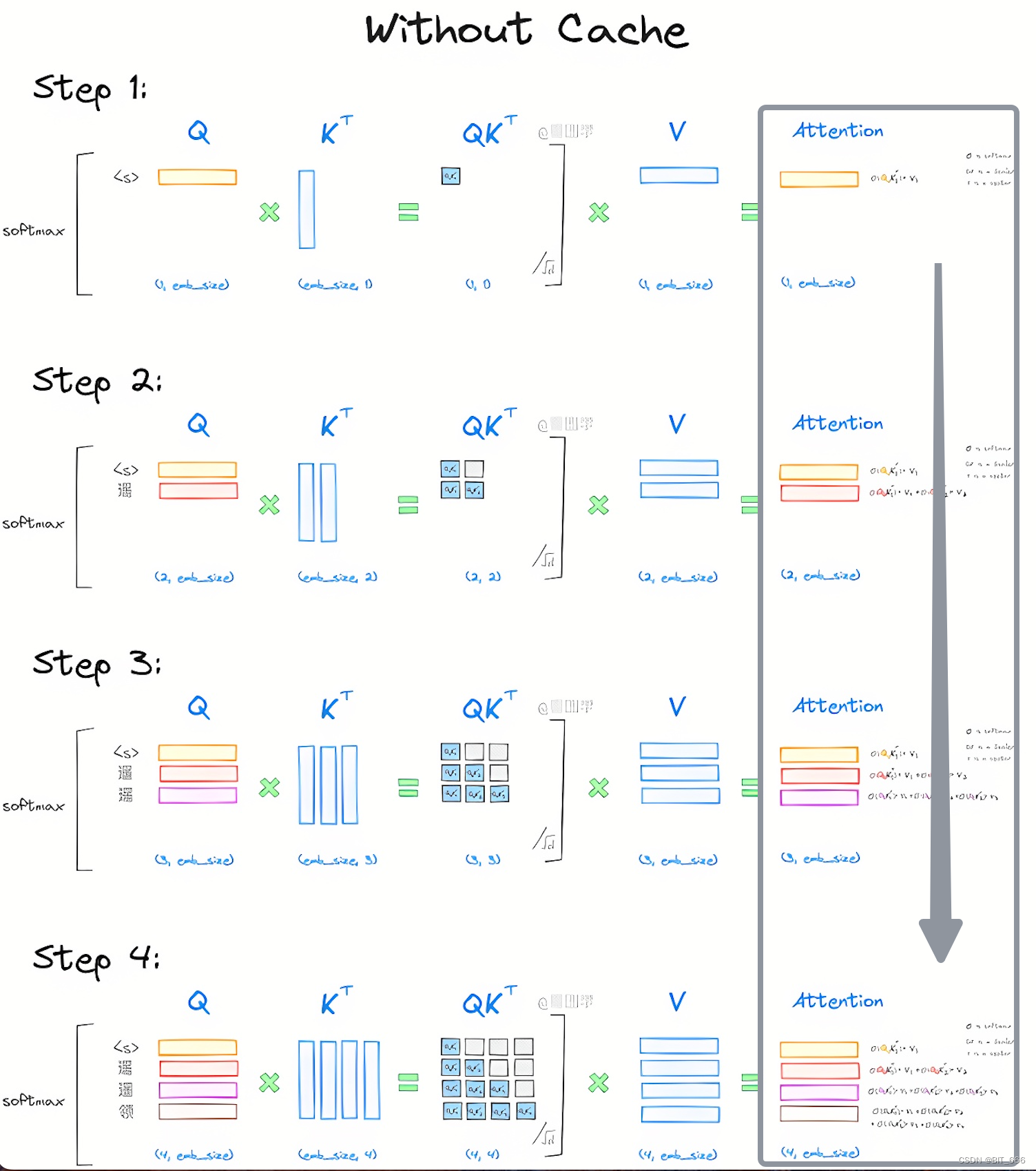
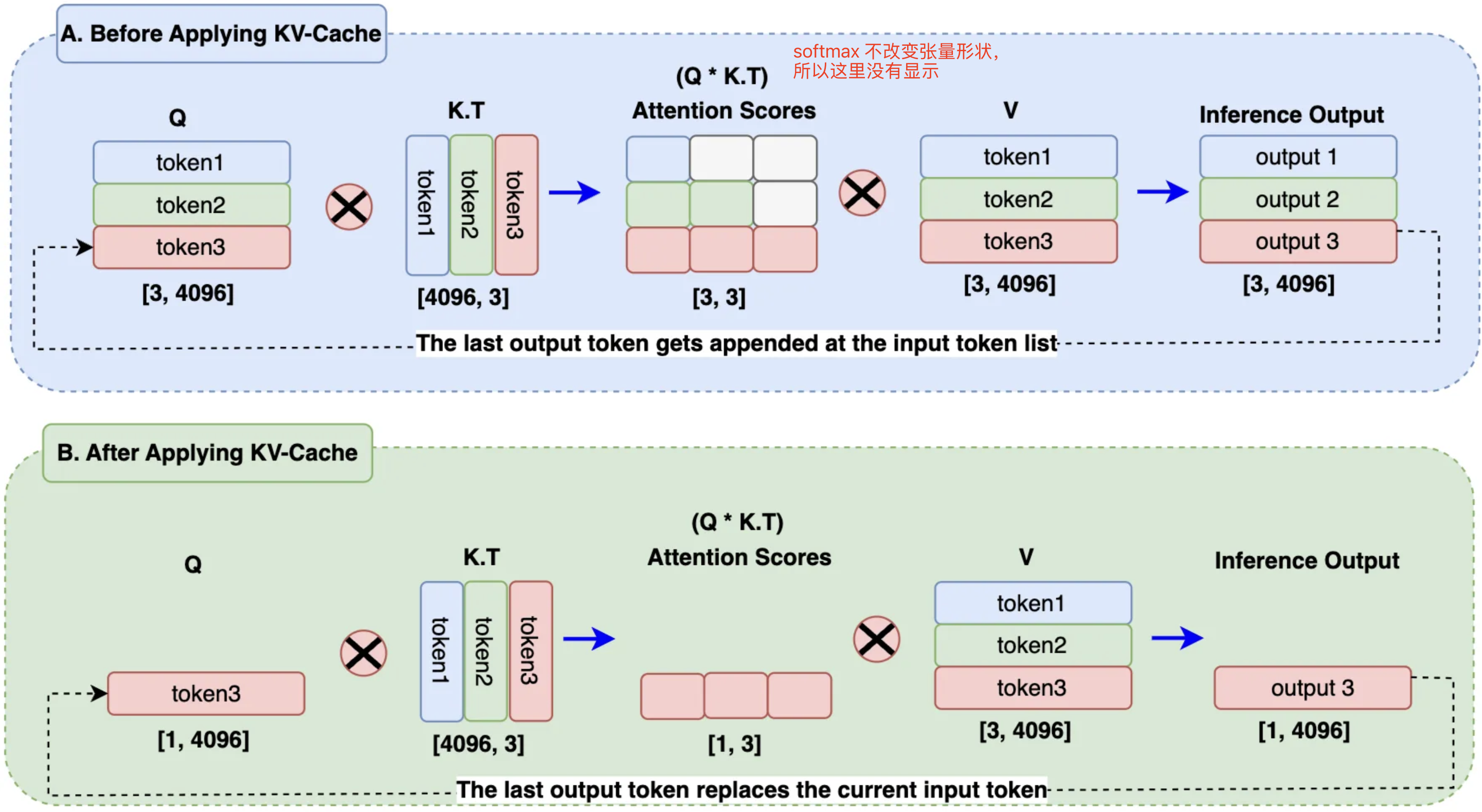
Understanding and Coding the KV Cache in LLMs from Scratch
KV Cache in LLMs: How It Speeds Up Inference and Solves Memory ...
KV Cache: The Hidden Optimization Behind Real-Time AI Responses
[论文评述] KeepKV: Eliminating Output Perturbation in KV Cache Compression ...
LLM 推理优化之 KV Cache - 知乎
Mastering LLM Techniques: Inference Optimization – GIXtools
KV Caches and Time-to-First-Token: Optimizing LLM Performance
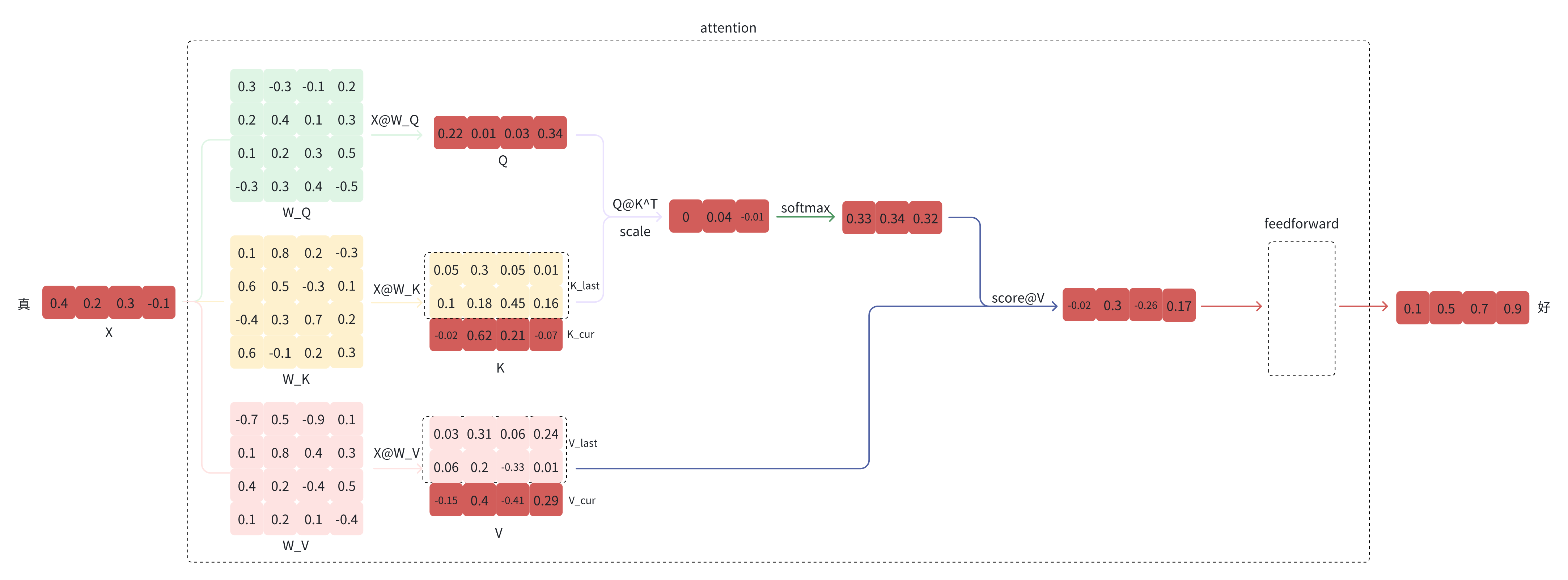
LLM - Generate With KV-Cache 图解与实践 By GPT-2_llm kv cache-CSDN博客
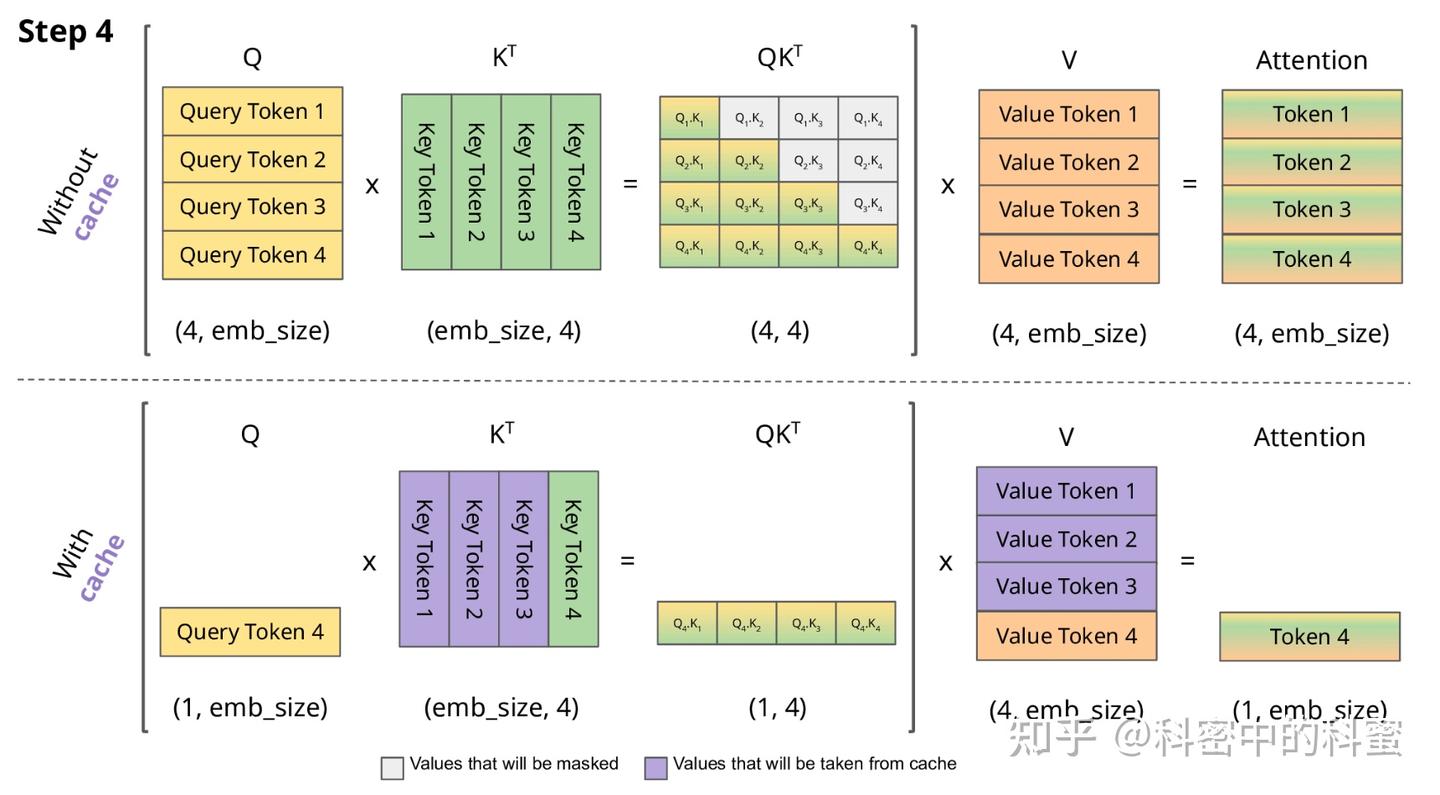
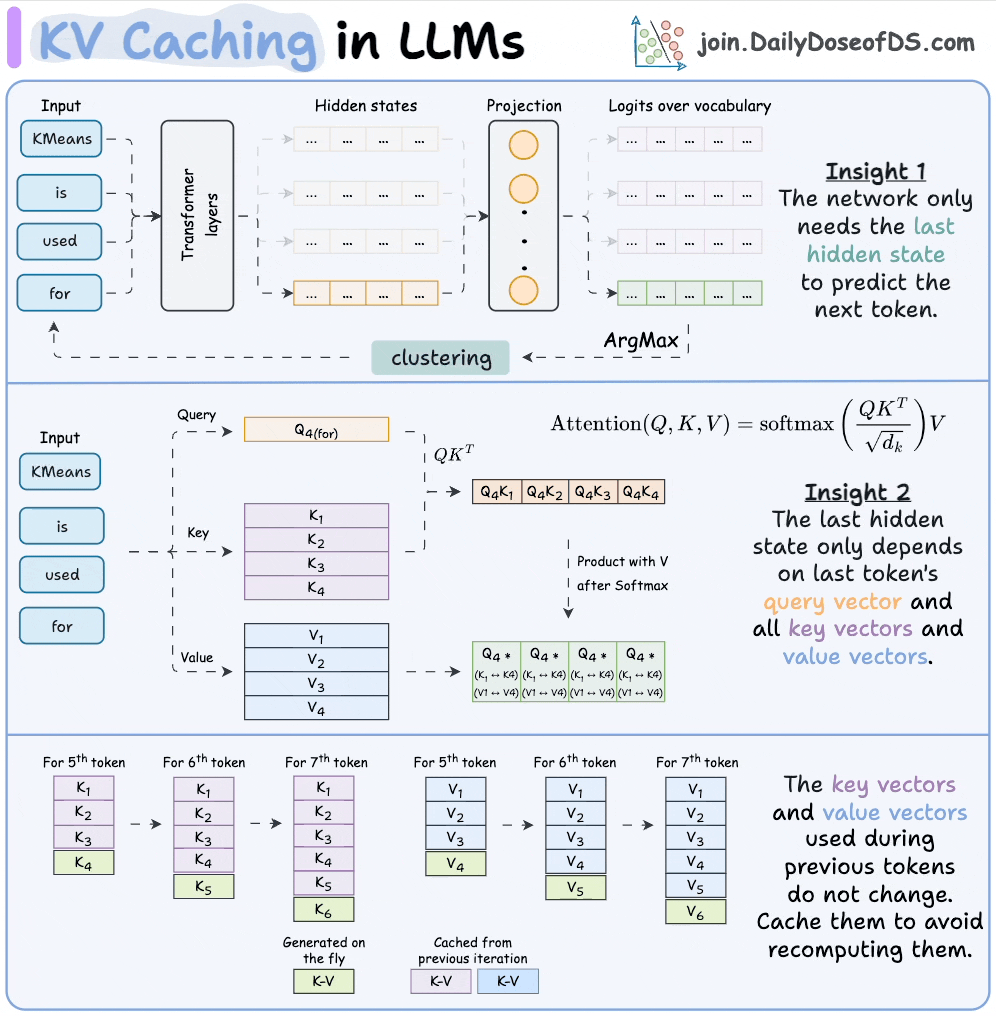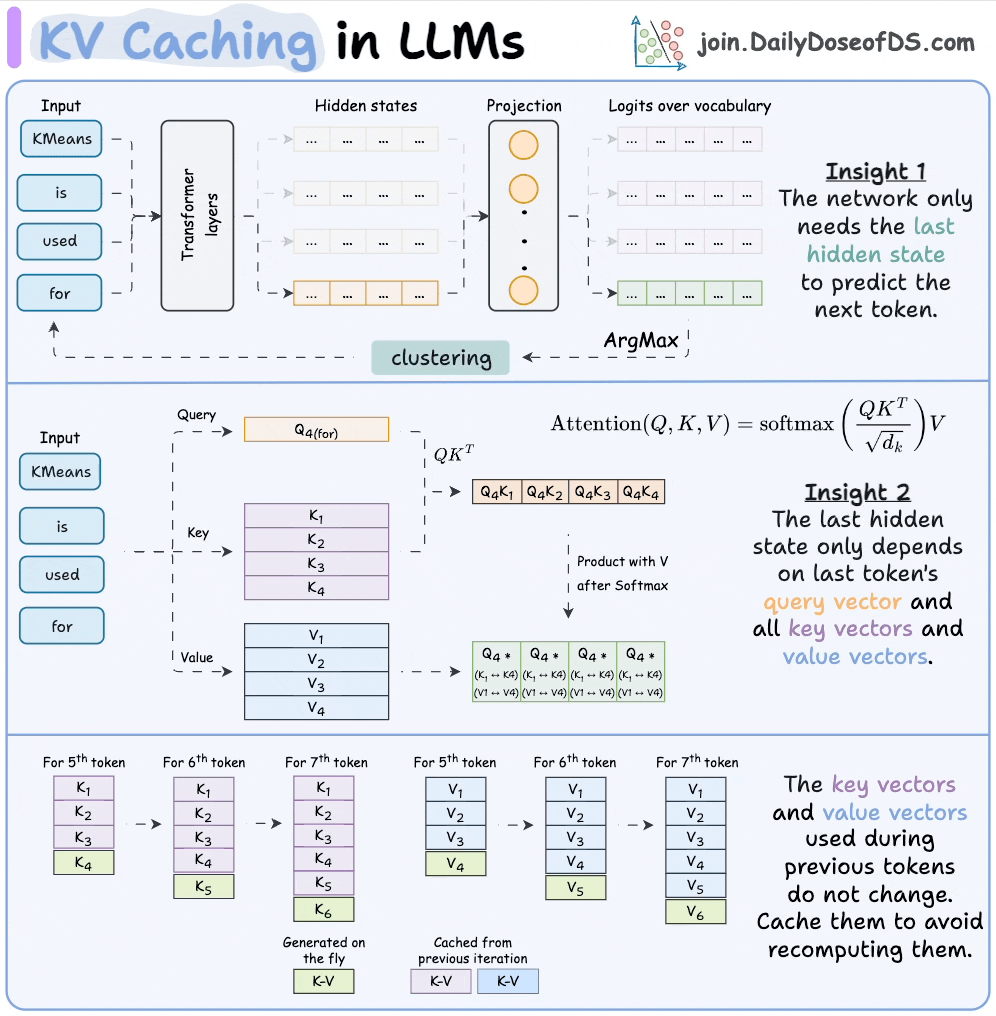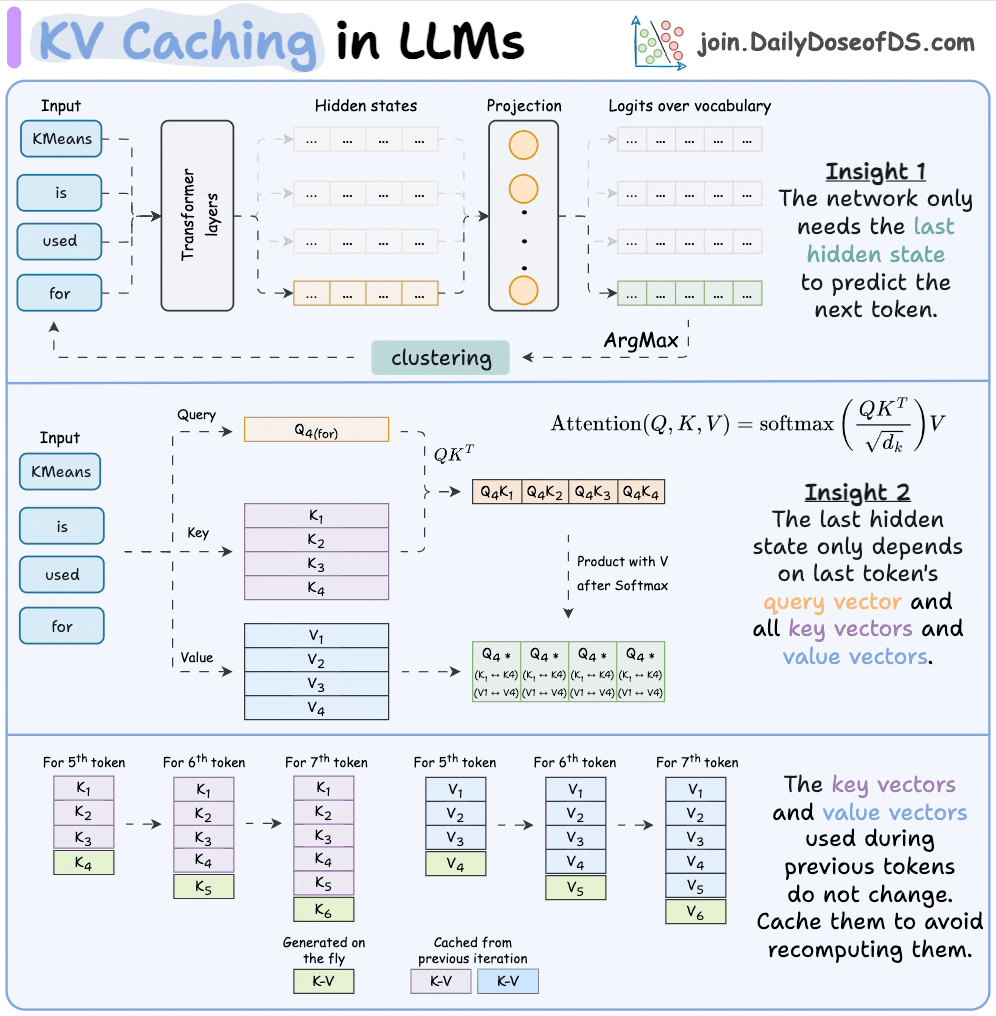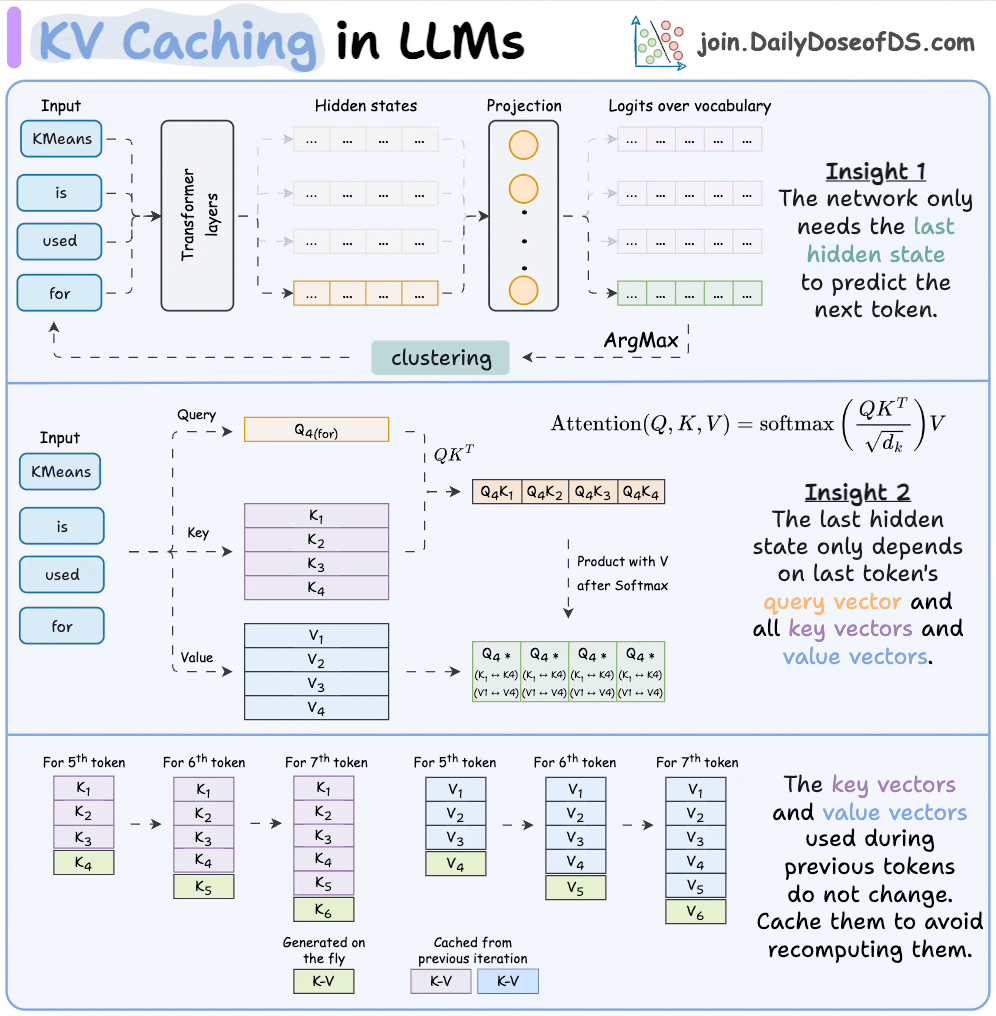
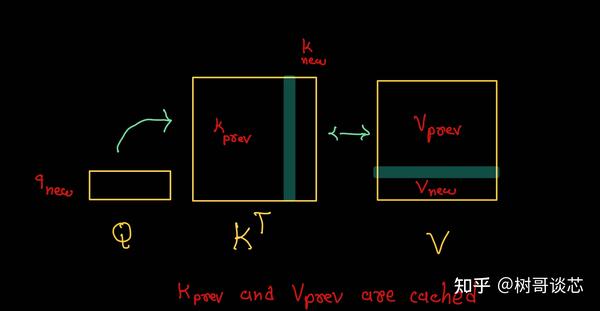
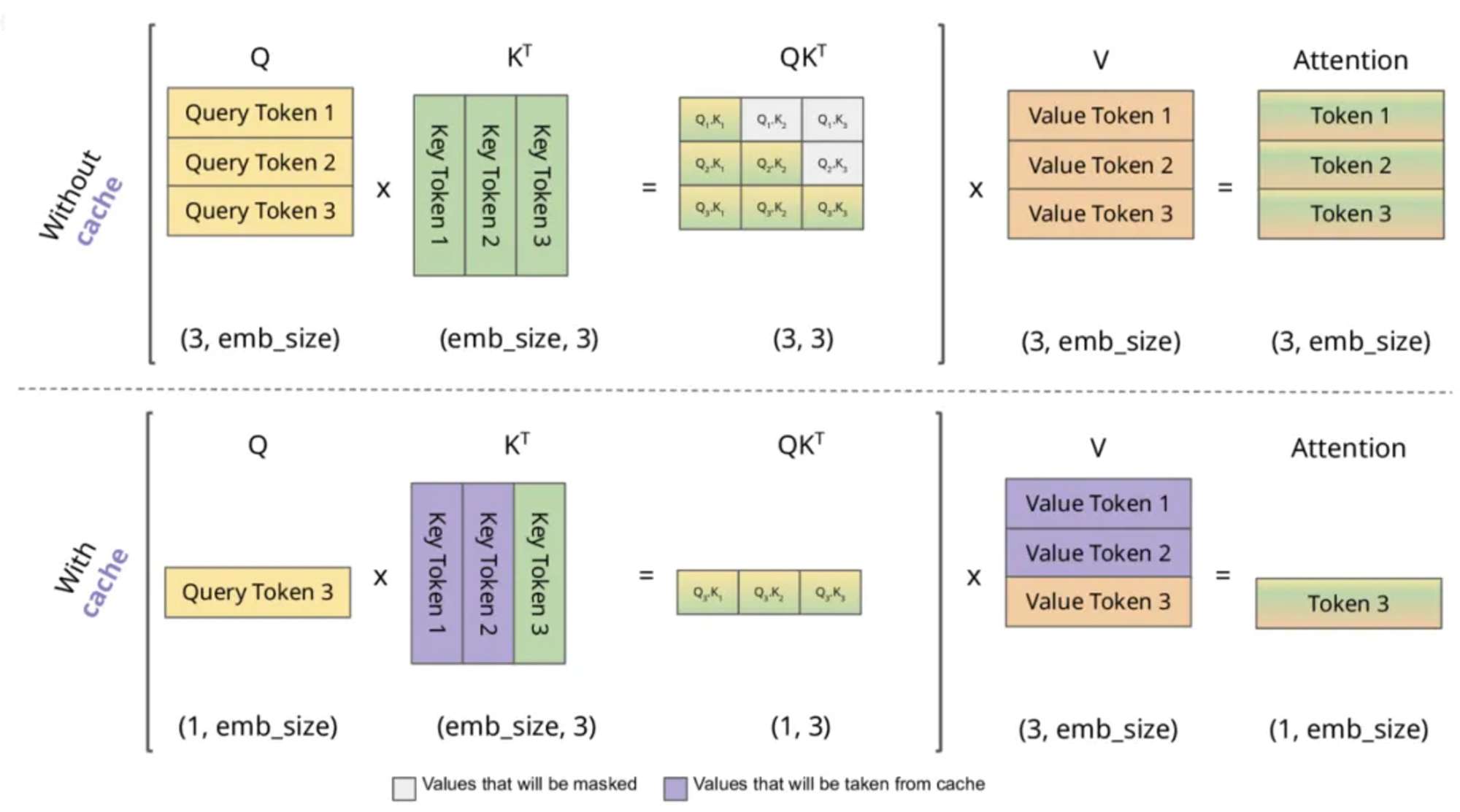
KV Caching in LLMs, Explained Visually. - by Avi Chawla
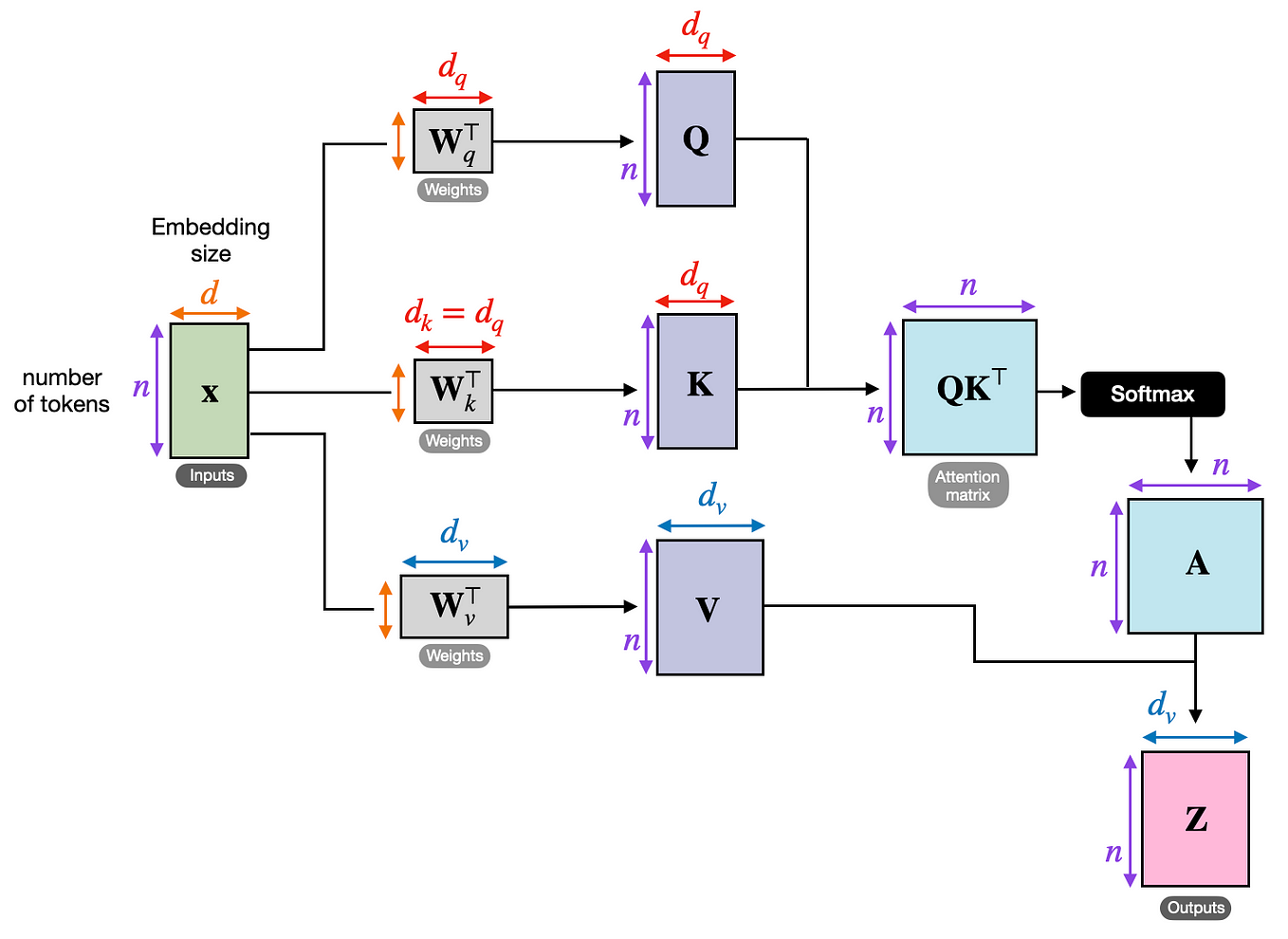
LLM Inference Series: 3. KV caching explained | by Pierre Lienhart | Medium
Entropy-Guided KV Caching for Efficient LLM Inference
LLM Inference Series: 4. KV caching, a deeper look | by Pierre Lienhart ...
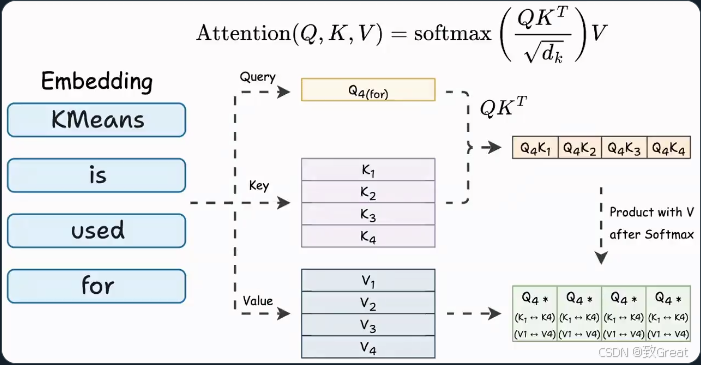
KV Cache量化技术详解:深入理解LLM推理性能优化 - 知乎
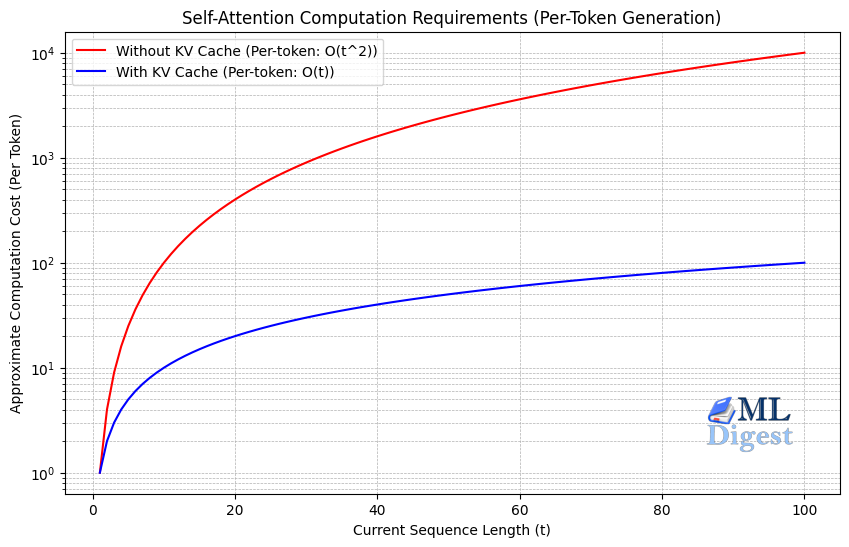
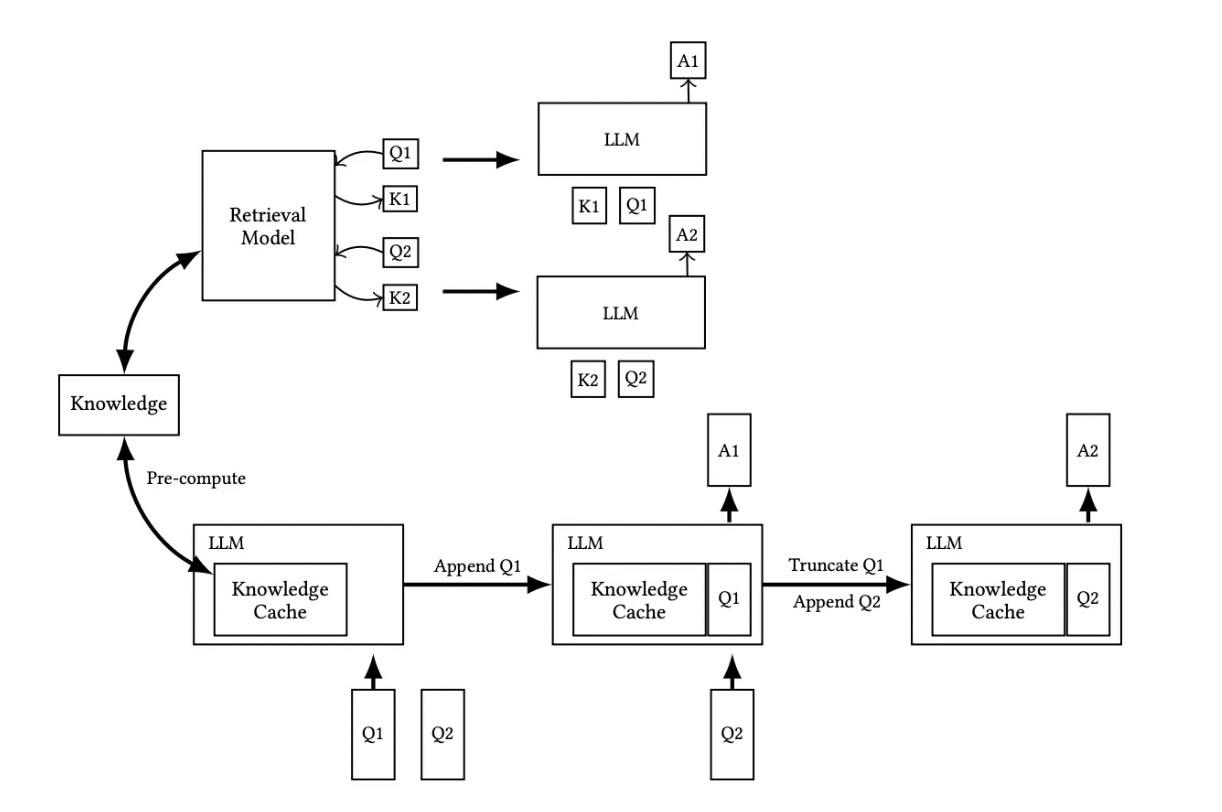
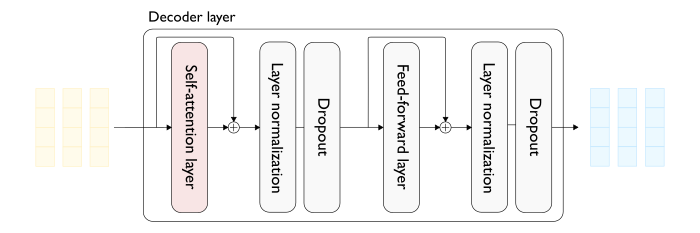
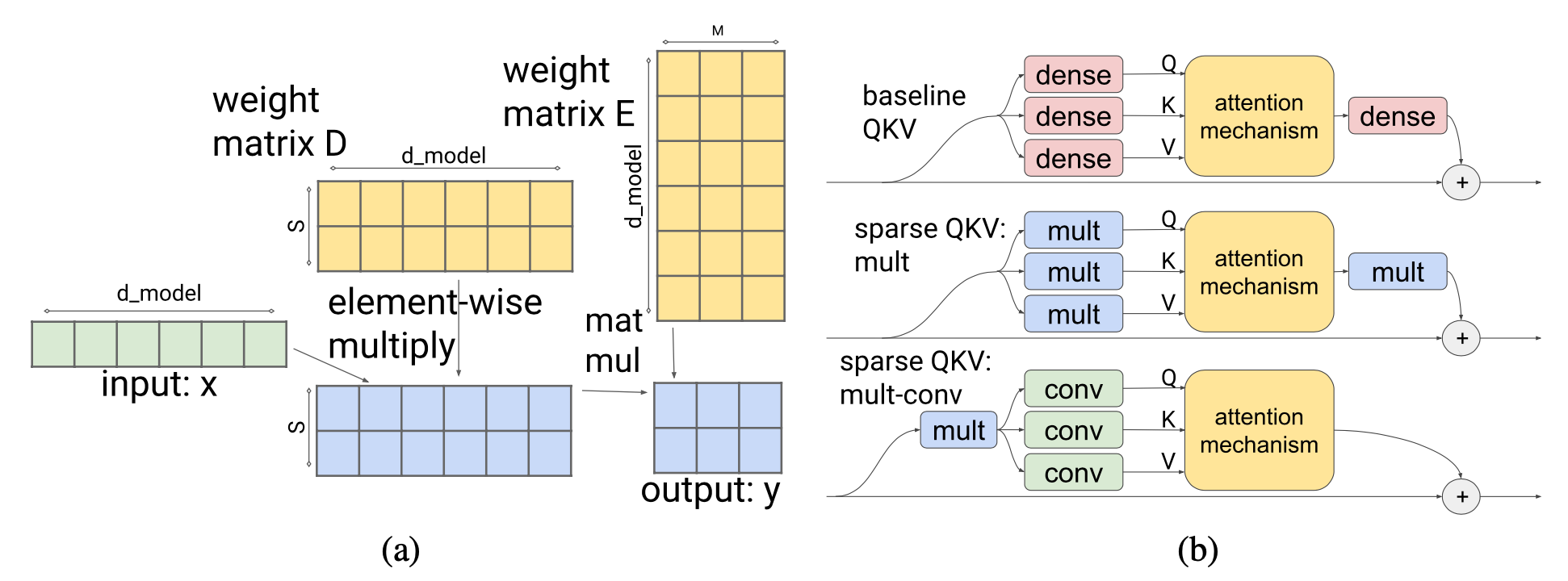
Understanding KV Caching: The Key To Efficient LLM Inference - ML Digest
Large Transformer Model Inference Optimization | Lil'Log
KV Caching Explained: Optimizing Transformer Inference Efficiency
KV Cache量化技术详解:深入理解LLM推理性能优化_ollama kv cache-CSDN博客
Efficient AI: KV Caching and KV Sharing | Gaurav's Blog
KV Caching in LLMs, explained visually
LLM Inference加速之KV Cache - 知乎
KV Cache:图解大模型推理加速方法_kvcache图解-CSDN博客
大模型推理加速:KV Cache Sparsity(稀疏化)方法 - 知乎
What is the KV cache? | Matt Log
LLM推理的KV cache - 知乎
How KV Caching Works in Large Language Models | MatterAI Blog
Transformers KV Caching Explained | by João Lages | Medium
20. Inference Acceleration (WIP) — LLM Foundations
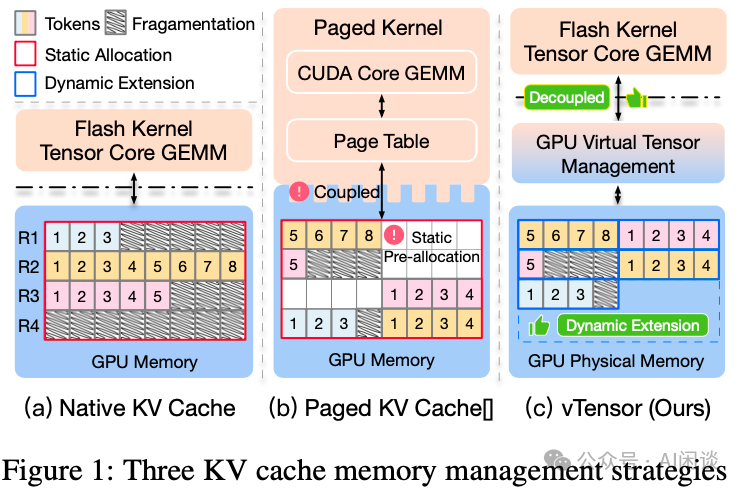
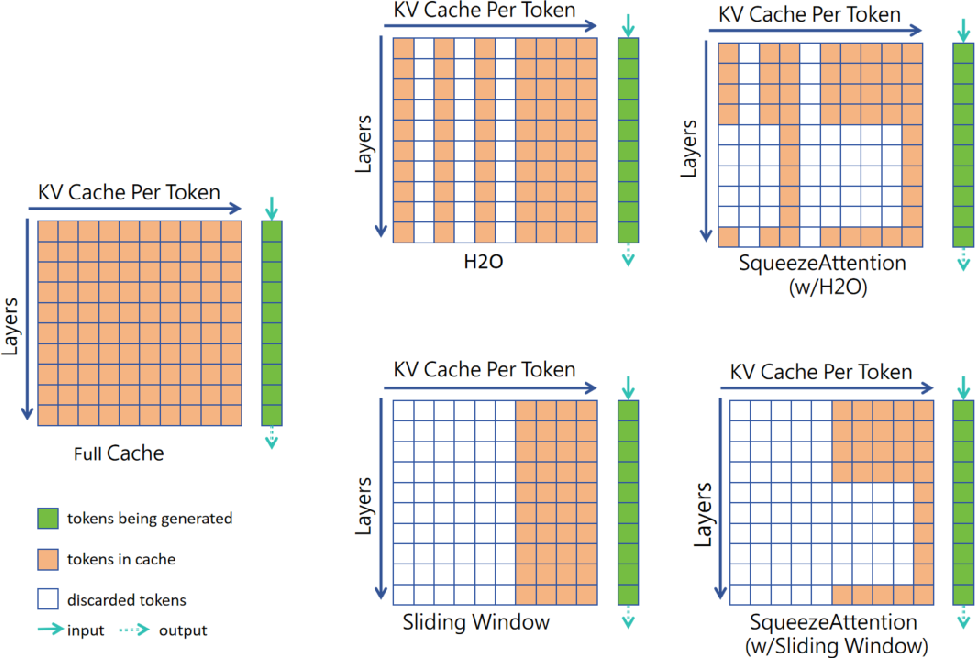
Figure 1 from SqueezeAttention: 2D Management of KV-Cache in LLM ...
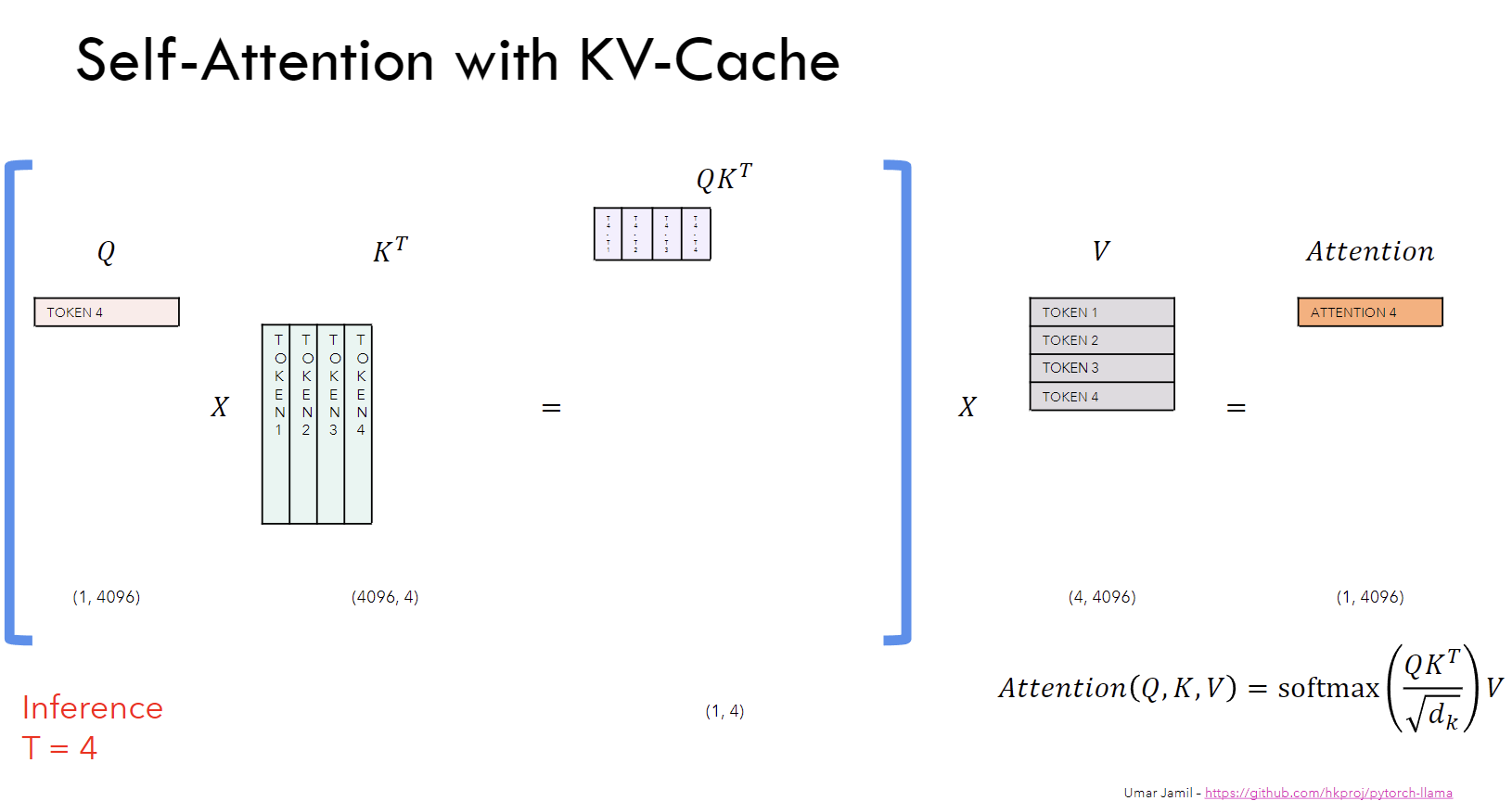
Implementing KV-Caching from Scratch | Detailed LLM Inference ...
A Guide to LLM Inference (Part 1): Foundations – Stephen Carmody
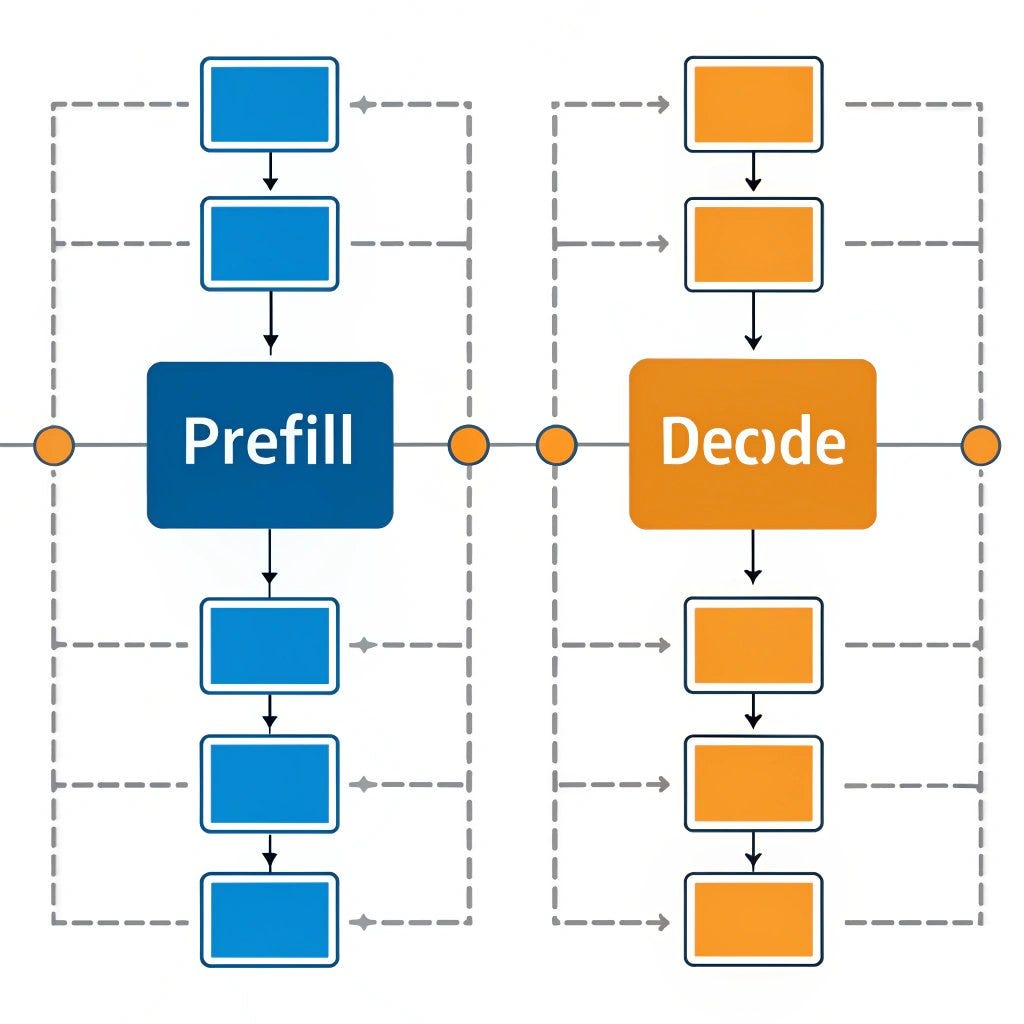
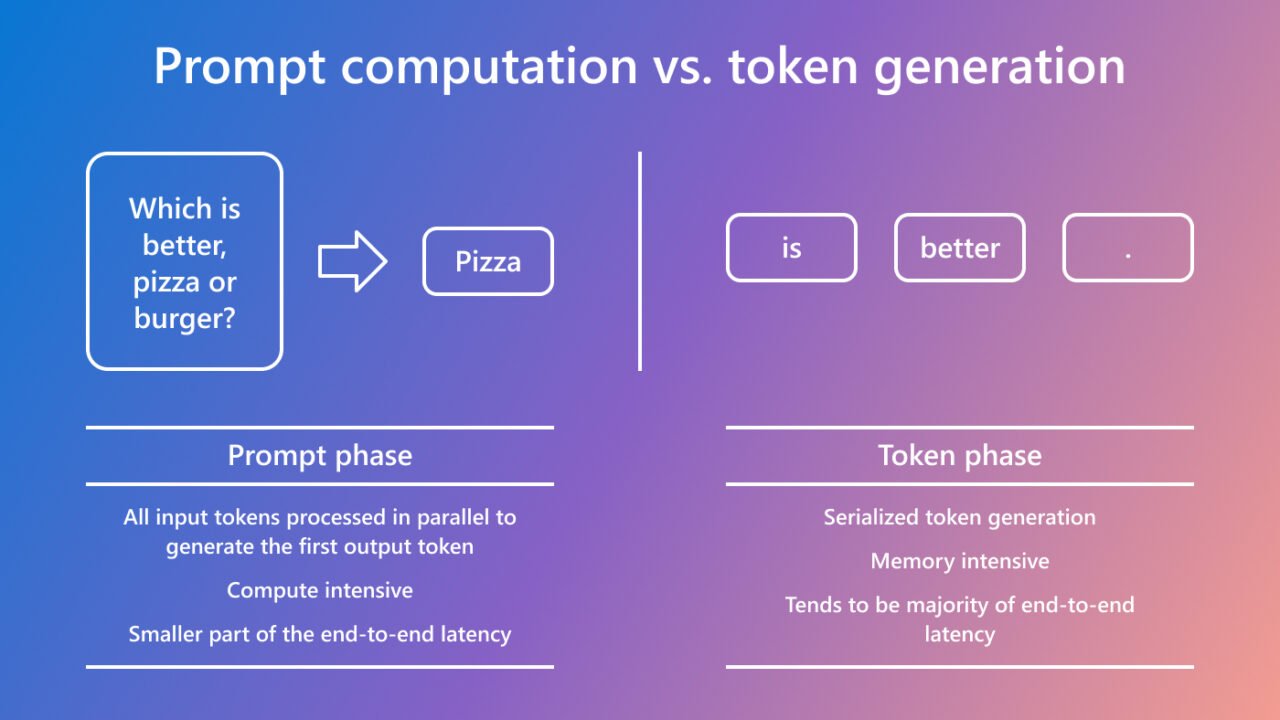
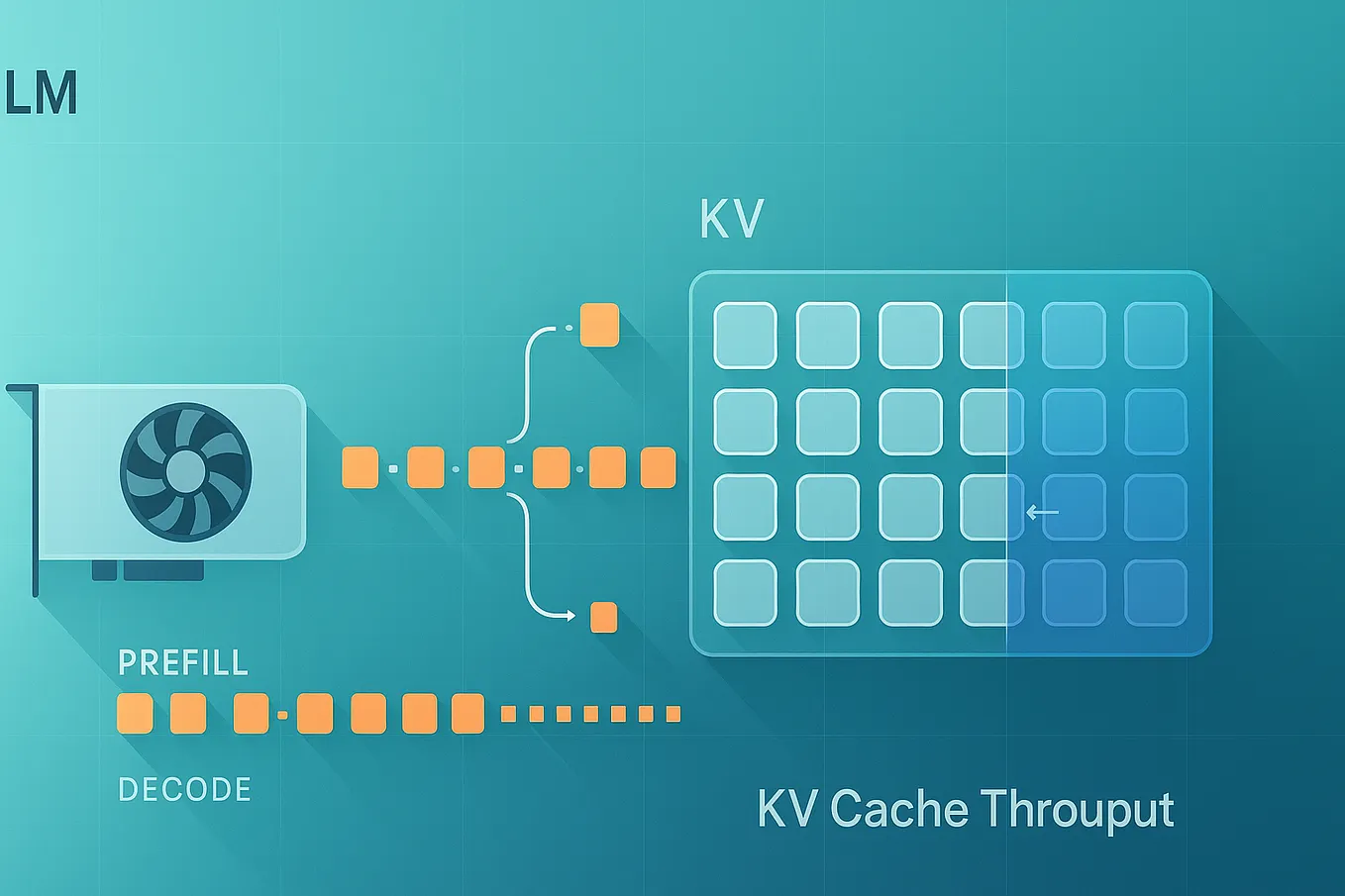
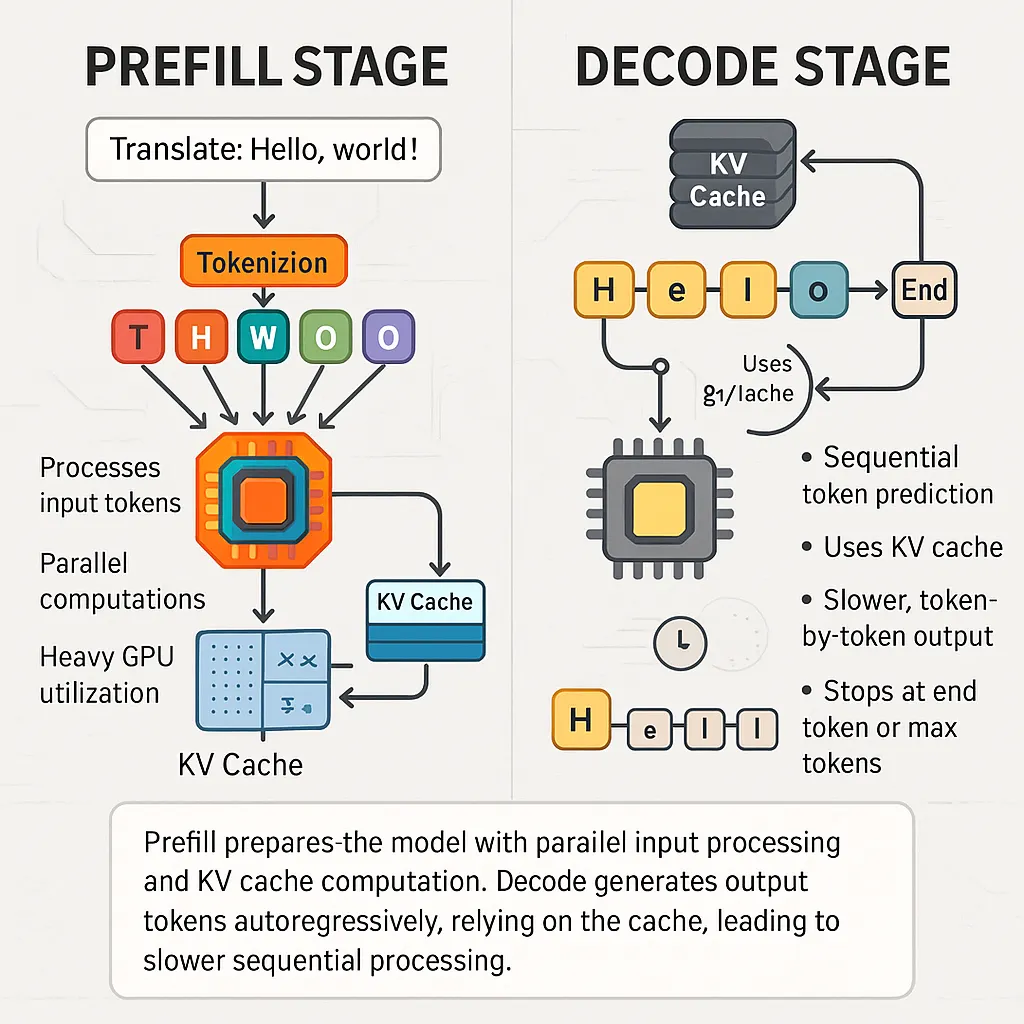
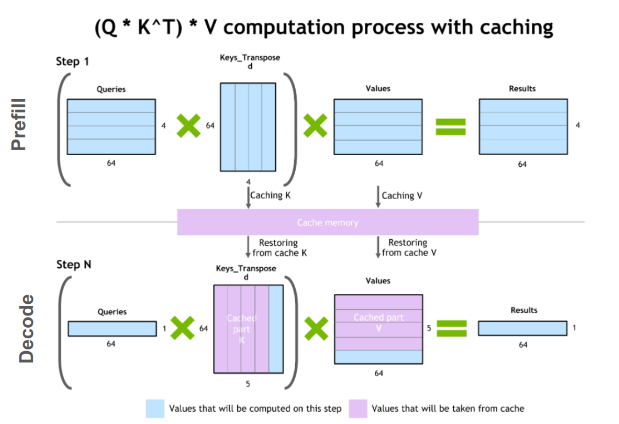
Understanding the Two Key Stages of LLM Inference: Prefill and Decode ...
Optimizing Inference for Long Context and Large Batch Sizes with NVFP4 ...
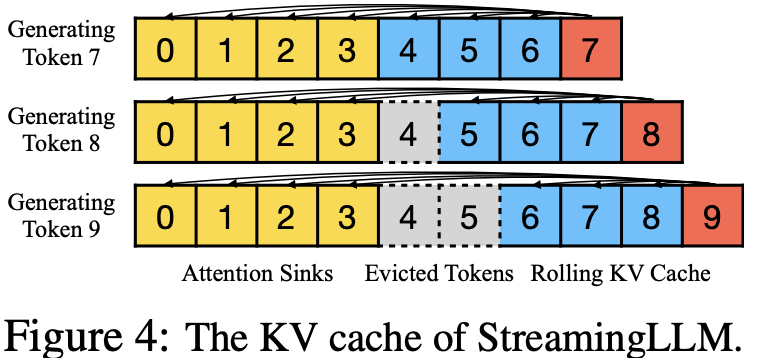
LLM推理加速:kv cache优化方法汇总 - 知乎
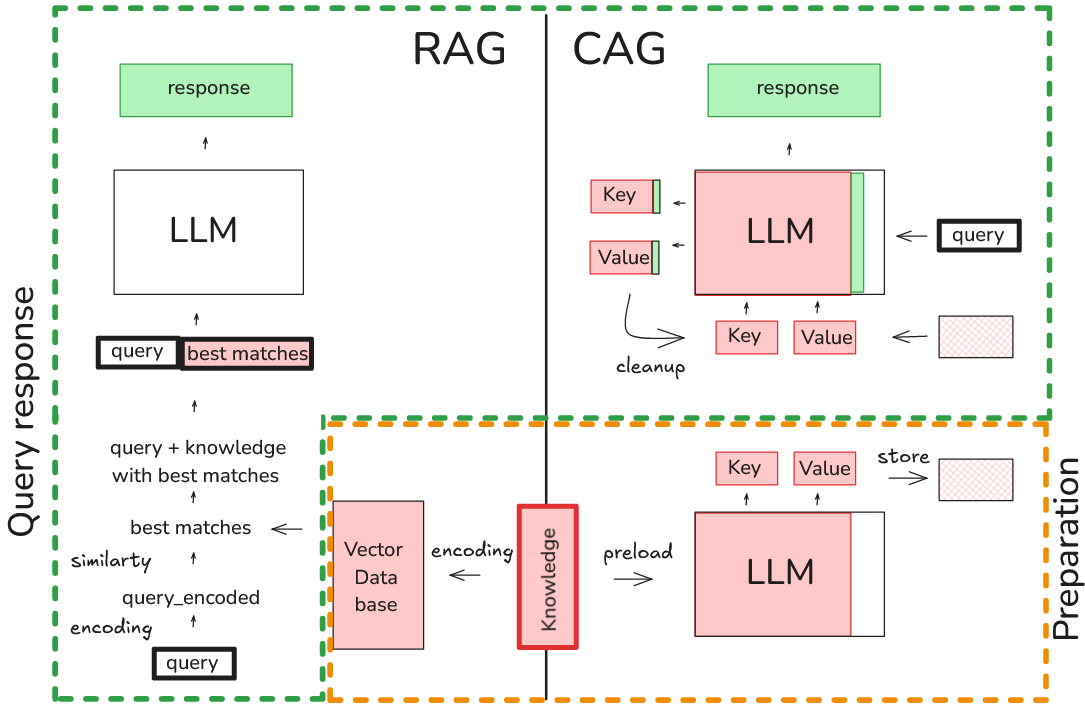
Mastering Long Contexts in LLMs with KVPress
Understanding ONNX: An Open Standard for Deep Learning Model ...
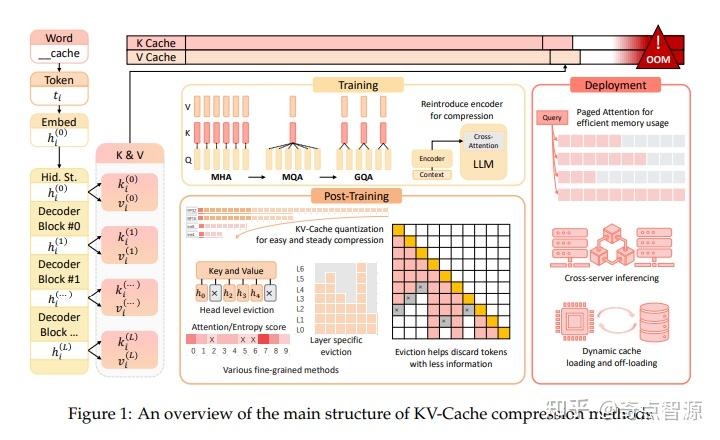
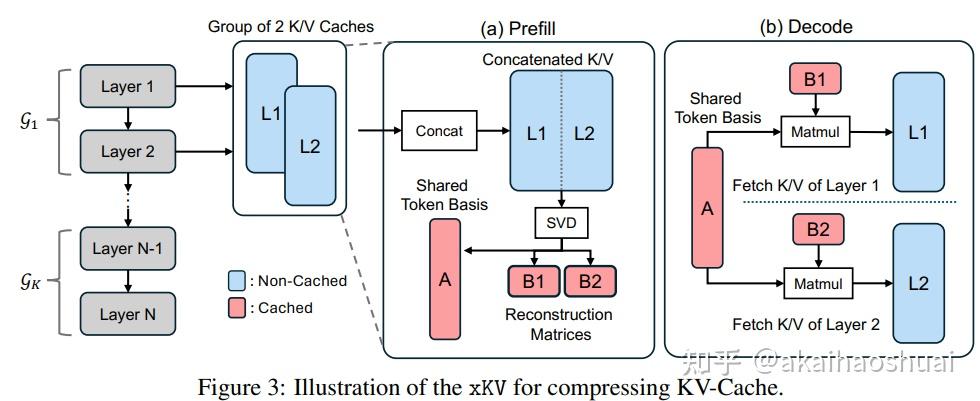
压缩KV-Cache:提升LLM效率与性能的关键 - 知乎
图解KV Cache:解锁LLM推理效率的关键-腾讯云开发者社区-腾讯云
LLM推理优化技术综述:KVCache、PageAttention、FlashAttention、MQA、GQA - 知乎
kv-cache 原理及优化概述 - Zhang
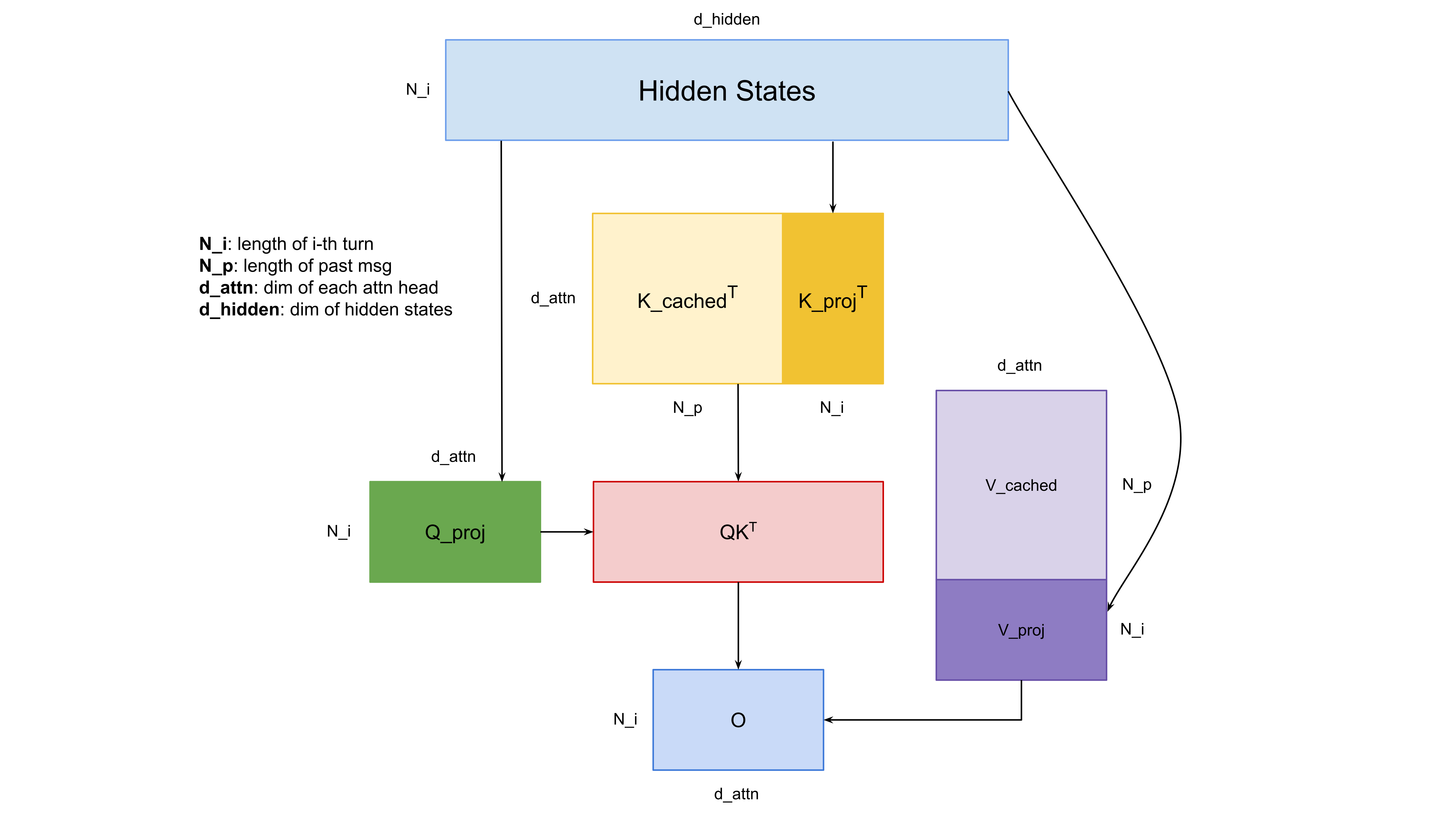
Efficient Forward Pass for Agent RL: Solving Multi-Turn Context ...
GitHub - jjiantong/Awesome-KV-Cache-Optimization: [Survey] Towards ...